
强化学习 × Web3 的真正机会不在于复制一个去中心化版 OpenAI,而在于重写「智能生产关系」
撰文:0xjacobzhao
本独立研报由IOSG Ventures支持,研究与写作过程受 Sam Lehman(Pantera Capital) 强化学习研报的启发,感谢 Ben Fielding (Gensyn.ai), Gao Yuan(Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang 对本文提出的宝贵建议。本文力求内容客观准确,部分观点涉及主观判断,难免存在偏差,敬请读者予以理解。
人工智能正从以「模式拟合」为主的统计学习,迈向以「结构化推理」为核心的能力体系,后训练(Post-training)的重要性快速上升。DeepSeek-R1 的出现标志着强化学习在大模型时代的范式级翻身,行业共识形成:预训练构建模型的通用能力基座,强化学习不再只是价值对齐工具,而被证明能够系统提升推理链质量与复杂决策能力,正逐步演化为持续提升智能水平的技术路径。
与此同时,Web3 正通过去中心化算力网络与加密激励体系重构 AI 的生产关系,而强化学习对 rollout 采样、奖励信号与可验证训练的结构性需求,恰与区块链的算力协作、激励分配与可验证执行天然契合。本研报将系统拆解 AI 训练范式与强化学习技术原理,论证强化学习 × Web3 的结构优势,并对 Prime Intellect、Gensyn、Nous Research、Gradient、Grail 和 Fraction AI 等项目进行分析。
一. AI 训练的三阶段:预训练、指令微调与后训练对齐
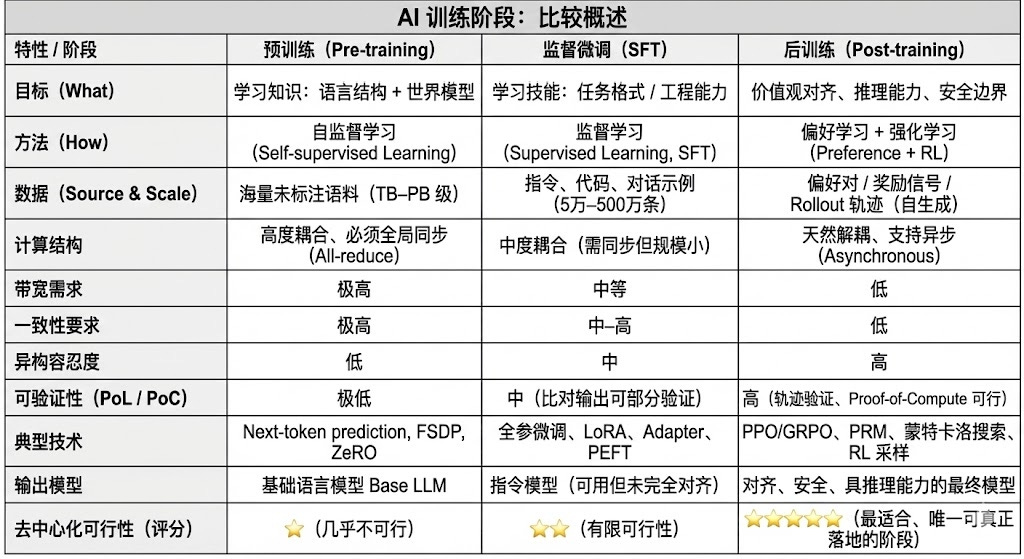
现代大语言模型(LLM)训练全生命周期通常被划分为三个核心阶段:预训练(Pre-training)、监督微调(SFT)和后训练(Post-training/RL)。三者分别承担「构建世界模型—注入任务能力—塑造推理与价值观」的功能,其计算结构、数据要求与验证难度决定了去中心化的匹配程度。
- 预训练(Pre-training) 通过大规模自监督学习(Self-supervised Learning)构建模型的语言统计结构与跨模态世界模型,是 LLM 能力的根基。此阶段需在万亿级语料上以全局同步方式训练,依赖数千至数万张 H100 的同构集群,成本占比高达 80–95%,对带宽与数据版权极度敏感,因此必须在高度集中式环境中完成。
- 微调(Supervised Fine-tuning)用于注入任务能力与指令格式,数据量小、成本占比约 5–15%,微调既可以进行全参训练,也可以采用参数高效微调(PEFT)方法,其中 LoRA、Q-LoRA 与 Adapter 是工业界主流。但仍需同步梯度,使其去中心化潜力有限。
- 后训练(Post-training)由多个迭代子阶段构成,决定模型的推理能力、价值观与安全边界,其方法既包括强化学习体系(RLHF、RLAIF、GRPO)也包括无 RL 的偏好优化方法(DPO),以及过程奖励模型(PRM)等。该阶段数据量与成本较低(5–10%),主要集中在 Rollout 与策略更新;其天然支持异步与分布式执行,节点无需持有完整权重,结合可验证计算与链上激励可形成开放的去中心化训练网络,是最适配 Web3 的训练环节。
二. 强化学习技术全景:架构、框架与应用
2.1 强化学习的系统架构与核心环节
强化学习(Reinforcement Learning, RL)通过「环境交互—奖励反馈—策略更新」驱动模型自主改进决策能力,其核心结构可视为由状态、动作、奖励与策略构成的反馈闭环。一个完整的 RL 系统通常包含三类组件:Policy(策略网络)、Rollout(经验采样)与 Learner(策略更新器)。策略与环境交互生成轨迹,Learner 根据奖励信号更新策略,从而形成持续迭代、不断优化的学习过程:
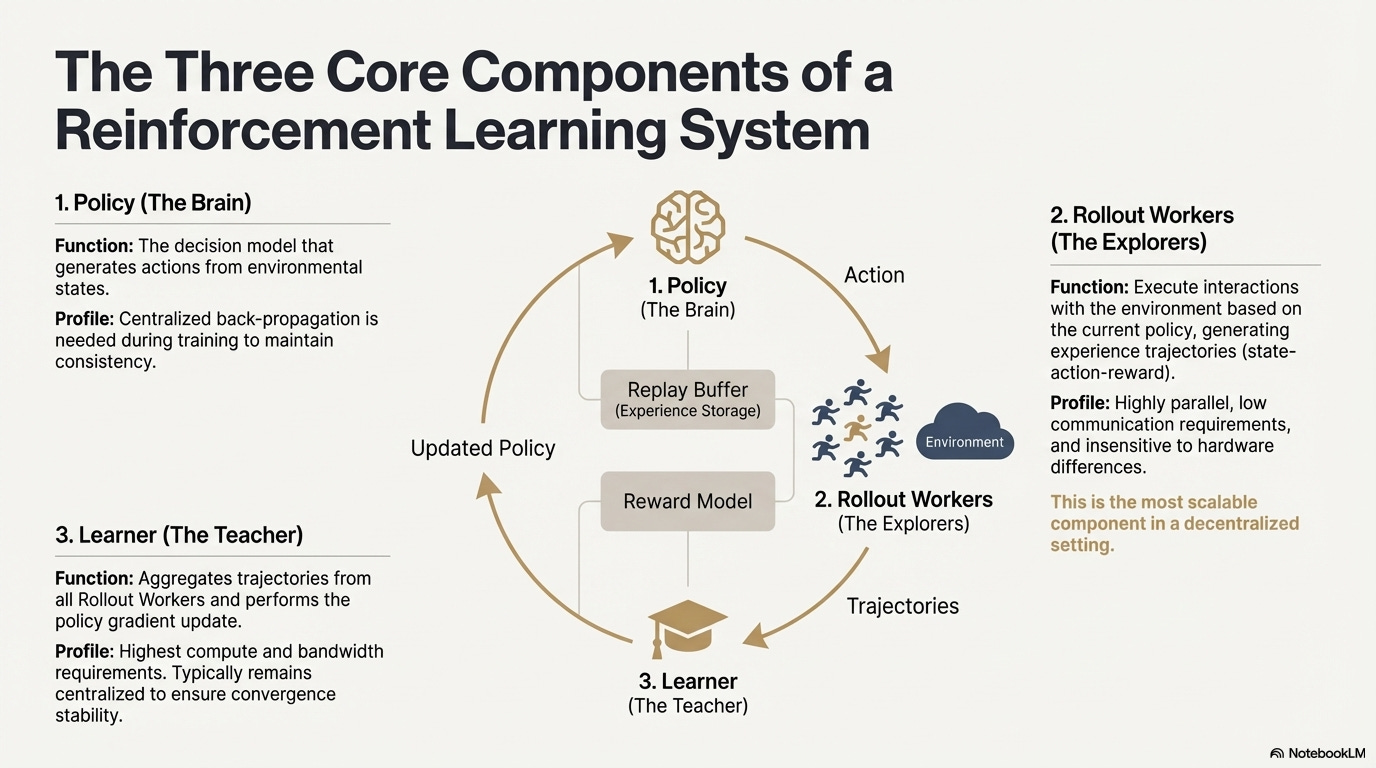
- 策略网络(Policy):从环境状态生成动作,是系统的决策核心。训练时需集中式反向传播维持一致性;推理时可分发至不同节点并行运行。
- 经验采样(Rollout):节点根据策略执行环境交互,生成状态—动作—奖励等轨迹。该过程高度并行、通信极低,对硬件差异不敏感是最适合在去中心化中扩展的环节。
- 学习器(Learner):聚合全部 Rollout 轨迹并执行策略梯度更新,是唯一对算力、带宽要求最高的模块,因此通常保持中心化或轻中心化部署以确保收敛稳定性。
2.2 强化学习阶段框架(RLHF → RLAIF → PRM → GRPO)
强化学习通常可分为五个阶段,整体流程如下所述:


数据生成阶段(Policy Exploration):在给定输入提示的条件下,策略模型 πθ 生成多条候选推理链或完整轨迹,为后续偏好评估与奖励建模提供样本基础,决定了策略探索的广度。
偏好反馈阶段(RLHF / RLAIF):
- RLHF(Reinforcement Learning from Human Feedback)通过多候选回答、人工偏好标注、训练奖励模型(RM)并用 PPO 优化策略,使模型输出更符合人类价值观,是 GPT-3.5 → GPT-4 的关键一环
- RLAIF(Reinforcement Learning from AI Feedback)以 AI Judge 或宪法式规则替代人工标注,实现偏好获取自动化,显著降低成本并具备规模化特性,已成为 Anthropic、OpenAI、DeepSeek 等的主流对齐范式。
奖励建模阶段(Reward Modeling):偏好对输入奖励模型,学习将输出映射为奖励。RM 教模型「什么是正确答案」,PRM 教模型「如何进行正确推理」。
- RM(Reward Model)用于评估最终答案的好坏,仅对输出打分:
- 过程奖励模型 PRM(Process Reward Model)它不再只评估最终答案,而是为每一步推理、每个 token、每个逻辑段打分,也是 OpenAI o1 与 DeepSeek-R1 的关键技术,本质上是在「教模型如何思考」。
奖励验证阶段(RLVR / Reward Verifiability):在奖励信号生成与使用过程中引入「可验证约束」,使奖励尽可能来自可复现的规则、事实或共识,从而降低 reward hacking 与偏差风险,并提升在开放环境中的可审计性与可扩展性。
策略优化阶段(Policy Optimization):是在奖励模型给出的信号指导下更新策略参数 θ,以得到更强推理能力、更高安全性与更稳定行为模式的策略 πθ′。主流优化方式包括:
- PPO(Proximal Policy Optimization): RLHF 的传统优化器,以稳定性见长,但在复杂推理任务中往往面临收敛慢、稳定性不足等局限。
- GRPO(Group Relative Policy Optimization):是 DeepSeek-R1 的核心创新,通过对候选答案组内优势分布进行建模以估计期望价值,而非简单排序。该方法保留了奖励幅度信息,更适合推理链优化,训练过程更稳定,被视为继 PPO 之后面向深度推理场景的重要强化学习优化框架。
- DPO(Direct Preference Optimization):非强化学习的后训练方法:不生成轨迹、不建奖励模型,而是直接在偏好对上做优化,成本低、效果稳定,因而被广泛用于 Llama、Gemma 等开源模型的对齐,但不提升推理能力。
新策略部署阶段(New Policy Deployment):经过优化后的模型表现为:更强的推理链生成能力(System-2 Reasoning)、更符合人类或 AI 偏好的行为、更低的幻觉率、更高的安全性。模型在持续迭代中不断学习偏好、优化过程、提升决策质量,形成闭环。

2.3 强化学习的产业应用五大分类
强化学习(Reinforcement Learning)已从早期的博弈智能演进为跨产业的自主决策核心框架,其应用场景按照技术成熟度与产业落地程度,可归纳为五大类别,并在各自方向推动了关键突破。
- 博弈与策略系统(Game & Strategy):是 RL 最早被验证的方向,在 AlphaGo、AlphaZero、AlphaStar、OpenAI Five 等「完美信息 + 明确奖励」的环境中,RL 展示了可与人类专家比肩甚至超越的决策智能,为现代 RL 算法奠定基础。
- 机器人与具身智能(Embodied AI):RL 通过连续控制、动力学建模与环境交互,使机器人学习操控、运动控制和跨模态任务(如 RT-2、RT-X),正快速迈向产业化,是现实世界机器人落地的关键技术路线。
- 数字推理(Digital Reasoning / LLM System-2):RL + PRM 推动大模型从「语言模仿」走向「结构化推理」,代表成果包括 DeepSeek-R1、OpenAI o1/o3、Anthropic Claude 及 AlphaGeometry,其本质是在推理链层面进行奖励优化,而非仅评估最终答案。
- 自动化科学发现与数学优化(Scientific Discovery):RL 在无标签、复杂奖励与巨大搜索空间中寻找最优结构或策略,已实现 AlphaTensor、AlphaDev、Fusion RL 等基础突破,展现出超越人类直觉的探索能力。
- 经济决策与交易系统(Economic Decision-making & Trading):RL 被用于策略优化、高维风险控制与自适应交易系统生成,相较传统量化模型更能在不确定环境中持续学习,是智能金融的重要构成部分。
三. 强化学习与 Web3 的天然匹配
强化学习(RL)与 Web3 的高度契合,源于二者本质上都是「激励驱动系统」。RL 依赖奖励信号优化策略,区块链依靠经济激励协调参与者行为,使两者在机制层面天然一致。RL 的核心需求——大规模异构 Rollout、奖励分配与真实性验证——正是 Web3 的结构优势所在。
推理与训练解耦:强化学习的训练过程可明确拆分为两个阶段:
- Rollout ( 探索采样 ):模型基于当前策略生成大量数据,计算密集型但通信稀疏型的任务。它不需要节点间频繁通信,适合在全球分布的消费级 GPU 上并行生成。
- Update ( 参数更新 ):基于收集到的数据更新模型权重,需高带宽中心化节点完成。
「推理—训练解耦」天然契合去中心化的异构算力结构:Rollout 可外包给开放网络,通过代币机制按贡献结算,而模型更新保持集中化以确保稳定性。
可验证性 (Verifiability):ZK 与 Proof-of-Learning 提供了验证节点是否真实执行推理的手段,解决了开放网络中的诚实性问题。在代码、数学推理等确定性任务中,验证者只需检查答案即可确认工作量,大幅提升去中心化 RL 系统的可信度。
激励层,基于代币经济的反馈生产机制:Web3 的代币机制可直接奖励 RLHF/RLAIF 的偏好反馈贡献者,使偏好数据生成具备透明、可结算、无需许可的激励结构;质押与削减(Staking/Slashing)进一步约束反馈质量,形成比传统众包更高效且对齐的反馈市场。
多智能体强化学习(MARL)潜力:区块链本质上是公开、透明、持续演化的多智能体环境,账户、合约与智能体不断在激励驱动下调整策略,使其天然具备构建大规模 MARL 实验场的潜力。尽管仍在早期,但其状态公开、执行可验证、激励可编程的特性,为未来 MARL 的发展提供了原则性优势。
四. 经典 Web3 + 强化学习项目解析
基于上述理论框架,我们将对当前生态中最具代表性的项目进行简要分析:
Prime Intellect: 异步强化学习范式 prime-rl
Prime Intellect 致力于构建全球开放算力市场,降低训练门槛、推动协作式去中心化训练,并发展完整的开源超级智能技术栈。其体系包括:Prime Compute(统一云 / 分布式算力环境)、INTELLECT 模型家族(10B–100B+)、开放强化学习环境中心(Environments Hub)、以及大规模合成数据引擎(SYNTHETIC-1/2)。
Prime Intellect 核心基础设施组件 prime-rl 框架专为异步分布式环境设计与强化学习高度相关,其余包括突破带宽瓶颈的 OpenDiLoCo 通信协议、保障计算完整性的 TopLoc 验证机制等。
Prime Intellect 核心基础设施组件一览

技术基石:prime-rl 异步强化学习框架
prime-rl 是 Prime Intellect 的核心训练引擎,专为大规模异步去中心化环境设计,通过 Actor–Learner 完全解耦实现高吞吐推理与稳定更新。执行者 (Rollout Worker) 与 学习者 (Trainer) 不再同步阻塞,节点可随时加入或退出,只需持续拉取最新策略并上传生成数据即可:

- 执行者 Actor (Rollout Workers):负责模型推理和数据生成。Prime Intellect 创新性地在 Actor 端集成了 vLLM 推理引擎 。vLLM 的 PagedAttention 技术和连续批处理(Continuous Batching)能力,使得 Actor 能够以极高的吞吐量生成推理轨迹。
- 学习者 Learner (Trainer):负责策略优化。Learner 从共享的经验回放缓冲区(Experience Buffer)中异步拉取数据进行梯度更新,无需等待所有 Actor 完成当前批次。
- 协调器 (Orchestrator):负责调度模型权重与数据流。
prime-rl 的关键创新点:
- 完全异步(True Asynchrony):prime-rl 摒弃传统 PPO 的同步范式,不等待慢节点、无需批次对齐,使任意数量与性能的 GPU 都能随时接入,奠定去中心化 RL 的可行性。
- 深度集成 FSDP2 与 MoE:通过 FSDP2 参数切片与 MoE 稀疏激活,prime-rl 让百亿级模型在分布式环境中高效训练,Actor 仅运行活跃专家,大幅降低显存与推理成本。
- GRPO+(Group Relative Policy Optimization):GRPO 免除 Critic 网络,显著减少计算与显存开销,天然适配异步环境,prime-rl 的 GRPO+ 更通过稳定化机制确保高延迟条件下的可靠收敛。
INTELLECT 模型家族:去中心化 RL 技术成熟度的标志
- INTELLECT-1(10B,2024 年 10 月)首次证明 OpenDiLoCo 能在跨三大洲的异构网络中高效训练(通信占比 <2%、算力利用率 98%),打破跨地域训练的物理认知;
- INTELLECT-2(32B,2025 年 4 月)作为首个 Permissionless RL 模型,验证 prime-rl 与 GRPO+ 在多步延迟、异步环境中的稳定收敛能力,实现全球开放算力参与的去中心化 RL;
- INTELLECT-3(106B MoE,2025 年 11 月)采用仅激活 12B 参数的稀疏架构,在 512×H200 上训练并实现旗舰级推理性能(AIME 90.8%、GPQA 74.4%、MMLU-Pro 81.9% 等),整体表现已逼近甚至超越规模远大于自身的中心化闭源模型。
Prime Intellect 此外还构建了数个支撑性基础设施:OpenDiLoCo 通过时间稀疏通信与量化权重差,将跨地域训练的通信量降低数百倍,使 INTELLECT-1 在跨三洲网络仍保持 98% 利用率;TopLoc + Verifiers 形成去中心化可信执行层,以激活指纹与沙箱验证确保推理与奖励数据的真实性;SYNTHETIC 数据引擎 则生产大规模高质量推理链,并通过流水线并行让 671B 模型在消费级 GPU 集群上高效运行。这些组件为去中心化 RL 的数据生成、验证与推理吞吐提供了关键的工程底座。INTELLECT 系列证明了这一技术栈可产生成熟的世界级模型,标志着去中心化训练体系从概念阶段进入实用阶段。
Gensyn: 强化学习核心栈 RL Swarm 与 SAPO
Gensyn 的目标是将全球闲置算力汇聚成一个开放、无需信任、可无限扩展的 AI 训练基础设施。其核心包括跨设备标准化执行层、点对点协调网络与无需信任的任务验证系统,并通过智能合约自动分配任务与奖励。围绕强化学习的特点,Gensyn 引入 RL Swarm、SAPO 与 SkipPipe 等核心机制等机制,将生成、评估、更新三个环节解耦,利用全球异构 GPU 组成的「蜂群」实现集体进化。其最终交付的不是单纯的算力,而是可验证的智能(Verifiable Intelligence)。
Gensyn 堆栈的强化学习应用

RL Swarm:去中心化的协作式强化学习引擎
RL Swarm 展示了一种全新的协作模式。它不再是简单的任务分发,而是一个模拟人类社会学习的去中心化的「生成—评估—更新」循环,类比协作式学习过程,无限循环:
- Solvers(执行者): 负责本地模型推理与 Rollout 生成,节点异构无碍。Gensyn 在本地集成高吞吐推理引擎(如 CodeZero),可输出完整轨迹而非仅答案。
- Proposers(出题者): 动态生成任务(数学题、代码问题等),支持任务多样性与类 Curriculum Learning 的难度自适应。
- Evaluators(评估者): 使用冻结的「裁判模型」或规则对本地 Rollout 进行评估,生成本地奖励信号。评估过程可被审计,减少作恶空间。
三者共同组成一个 P2P 的 RL 组织结构,无需中心化调度即可完成大规模协作学习。

SAPO:为去中心化重构的策略优化算法: SAPO(Swarm Sampling Policy Optimization)以「共享 Rollout 并过滤无梯度信号样本,而非共享梯度」为核心,通过大规模去中心化的 Rollout 采样,并将接收的 Rollout 视为本地生成,从而在无中心协调、节点延迟差异显著的环境中保持稳定收敛。相较依赖 Critic 网络、计算成本较高的 PPO,或基于组内优势估计的 GRPO,SAPO 以极低带宽使消费级 GPU 也能有效参与大规模强化学习优化。
通过 RL Swarm 与 SAPO,Gensyn 证明了强化学习(尤其是后训练阶段的 RLVR)天然适配去中心化架构——因为其更依赖于大规模、多样化的探索(Rollout),而非高频参数同步。结合 PoL 与 Verde 的验证体系,Gensyn 为万亿级参数模型的训练提供了一条不再依赖单一科技巨头的替代路径:一个由全球数百万异构 GPU 组成的、自我演化的超级智能网络。
Nous Research:可验证强化学习环境 Atropos
Nous Research 在构建一套 去中心化、可自我进化的认知基础设施。其核心组件——Hermes、Atropos、DisTrO、Psyche 与 World Sim 被组织成一个持续闭环的智能演化系统。不同于传统「预训练—后训练—推理」线性流程,Nous 采用 DPO、GRPO、拒绝采样等强化学习技术,将数据生成、验证、学习与推理统一为连续反馈回路,打造持续自我改进的闭环 AI 生态。
Nous Research 组件总览
模型层:Hermes 与推理能力的演进
Hermes 系列是 Nous Research 面向用户的主要模型接口,其演进清晰展示了行业从传统 SFT/DPO 对齐向推理强化学习(Reasoning RL)迁移的路径:
- Hermes 1–3:指令对齐与早期代理能力:Hermes 1–3 依靠低成本 DPO 完成稳健指令对齐,并在 Hermes 3 借助合成数据与首次引入的 Atropos 验证机制。
- Hermes 4 / DeepHermes:通过思维链将 System-2 式慢思考写入权重,以 Test-Time Scaling 提升数学与代码性能,并依赖「拒绝采样 + Atropos 验证」构建高纯度推理数据。
- DeepHermes 进一步采用 GRPO 替代难以分布式落地的 PPO,使推理 RL 能在 Psyche 去中心化 GPU 网络上运行,为开源推理 RL 的可扩展化奠定工程基础。
Atropos:可验证奖励驱动的强化学习环境
Atropos 是 Nous RL 体系的真正枢纽。它将提示、工具调用、代码执行和多轮交互封装成标准化 RL 环境,可直接验证输出是否正确,从而提供确定性奖励信号,替代昂贵且不可扩展的人类标注。更重要的是,在去中心化训练网络 Psyche 中,Atropos 充当「裁判」,用于验证节点是否真实提升策略,支持可审计的 Proof-of-Learning,从根本上解决分布式 RL 中的奖励可信性问题。

DisTrO 与 Psyche:去中心化强化学习的优化器层
传统 RLF(RLHF/RLAIF)训练依赖中心化高带宽集群,这是开源无法复制的核心壁垒。DisTrO 通过动量解耦与梯度压缩,将 RL 的通信成本降低几个数量级,使训练能够在互联网带宽上运行;Psyche 则将这一训练机制部署在链上网络,使节点可以在本地完成推理、验证、奖励评估与权重更新,形成完整的 RL 闭环。
在 Nous 的体系中, Atropos 验证思维链;DisTrO 压缩训练通信;Psyche 运行 RL 循环;World Sim 提供复杂环境;Forge 采集真实推理;Hermes 将所有学习写入权重。强化学习不仅是一个训练阶段,而是 Nous 架构中 连接数据、环境、模型与基础设施的核心协议,让 Hermes 成为一个 能在开源算力网络上持续自我改进的活体系统。
Gradient Network:强化学习架构 Echo
Gradient Network 核心愿景是通过「开放智能协议栈」(Open Intelligence Stack)重构 AI 的计算范式。Gradient 的技术栈由一组可独立演化、又异构协同的核心协议组成。其体系从底层通信到上层智能协作依次包括:Parallax(分布式推理)、Echo(去中心化 RL 训练)、Lattica(P2P 网络)、SEDM / Massgen / Symphony / CUAHarm(记忆、协作、安全)、VeriLLM(可信验证)、Mirage(高保真仿真),共同构成持续演化的去中心化智能基础设施。

Echo — 强化学习训练架构
Echo 是 Gradient 的强化学习框架,其核心设计理念在于解耦强化学习中的训练、推理与数据(奖励)路径,使 Rollout 生成、策略优化与奖励评估能够在异构环境中独立扩展与调度。在由推理侧与训练侧节点组成的异构网络中协同运行,以轻量同步机制在广域异构环境中维持训练稳定性,有效缓解传统 DeepSpeed RLHF / VERL 中推理与训练混跑导致的 SPMD 失效与 GPU 利用率瓶颈。
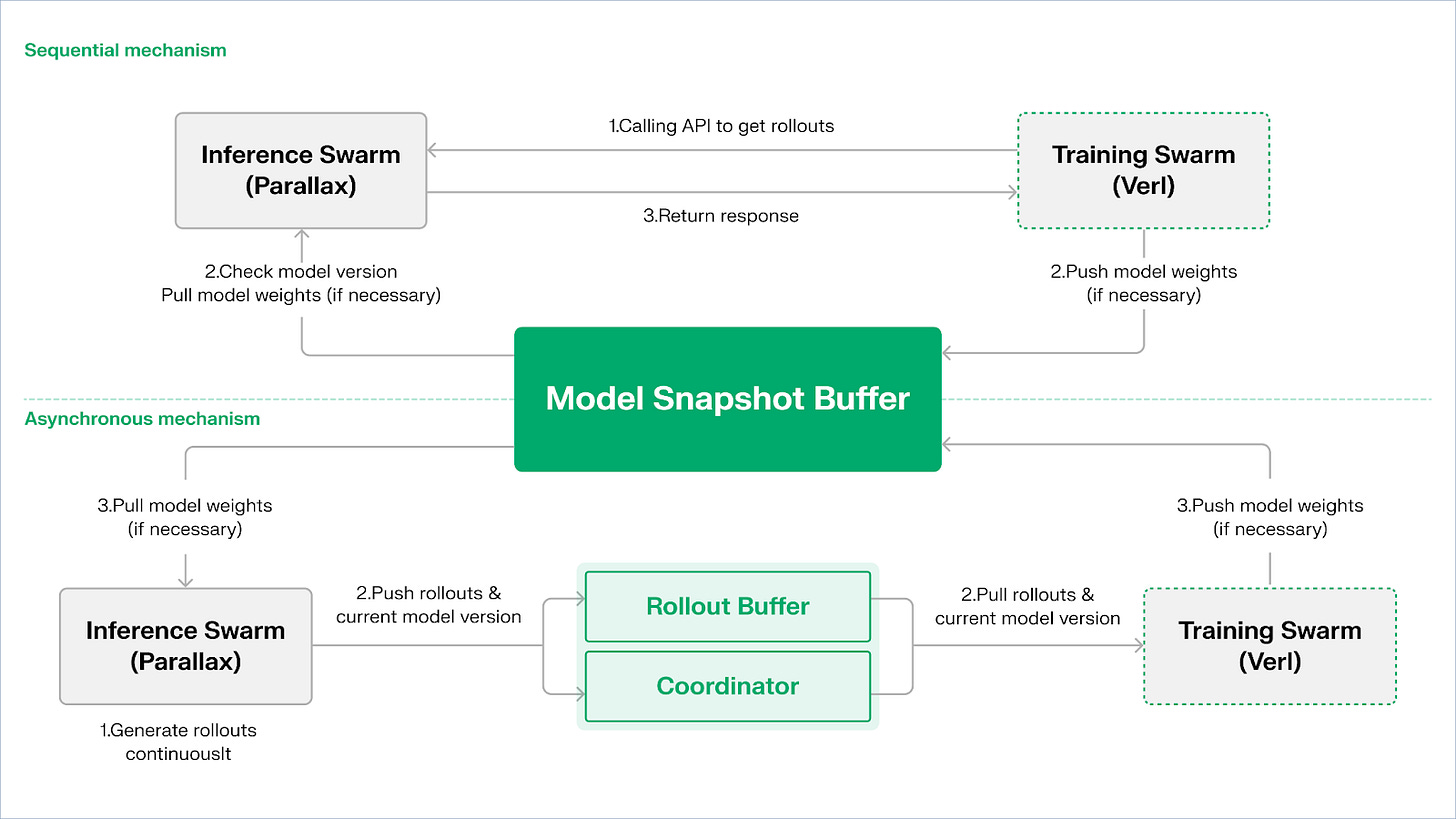
Echo 采用「推理–训练双群架构」实现算力利用最大化,双群各自独立运行,互不阻塞:
- 最大化采样吞吐:推理群 Inference Swarm 由消费级 GPU 与边缘设备组成,通过 Parallax 以 pipeline‐parallel 构建高吞吐采样器,专注于轨迹生成;
- 最大化梯度算力:训练群 Training Swarm 由可运行于中心化集群或全球多地的消费级 GPU 网络,负责梯度更新、参数同步与 LoRA 微调,专注于学习过程。
为维持策略与数据的一致性,Echo 提供 顺序(Sequential) 与异步(Asynchronous) 两类轻量级同步协议,实现策略权重与轨迹的双向一致性管理:
- 顺序拉取(Pull)模式|精度优先 :训练侧在拉取新轨迹前强制推理节点刷新模型版本,从而确保轨迹新鲜度,适合对策略陈旧高度敏感的任务;
- 异步推拉(Push–Pull)模式|效率优先:推理侧持续生成带版本标签的轨迹,训练侧依自身节奏消费,协调器监控版本偏差并触发权重刷新,最大化设备利用率。
在底层,Echo 构建于 Parallax(低带宽环境下的异构推理)与轻量化分布式训练组件(如 VERL) 之上,依赖 LoRA 降低跨节点同步成本,使强化学习可在全球异构网络上稳定运行。
Grail:Bittensor 生态的强化学习
Bittensor 通过其独特的 Yuma 共识机制,构建了一个巨大的、稀疏的、非平稳的奖励函数网络。
Bittensor 生态中的Covenant AI 则通过 SN3 Templar、SN39 Basilica 与 SN81 Grail 构建了从预训练到 RL 后训练的垂直一体化流水线。其中,SN3 Templar 负责基础模型的预训练,SN39 Basilica 提供分布式算力市场,SN81 Grail 则作为面向 RL 后训练的「可验证推理层」,承载 RLHF / RLAIF 的核心流程,完成从基础模型到对齐策略的闭环优化。

GRAIL 目标是以密码学方式证明每条强化学习 rollout 的真实性与模型身份绑定,确保 RLHF 能够在无需信任的环境中被安全执行。协议通过三层机制建立可信链条:
- 确定性挑战生成:利用 drand 随机信标与区块哈希生成不可预测但可复现的挑战任务(如 SAT、GSM8K),杜绝预计算作弊;
- 通过 PRF 索引采样与 sketch commitments,使验证者以极低成本抽检 token-level logprob 与推理链,确认 rollout 确由声明模型生成;
- 模型身份绑定:将推理过程与模型权重指纹及 token 分布的结构性签名绑定,确保替换模型或结果重放都会被立即识别。由此,为 RL 中推理轨迹(rollout)提供了真实性根基。
在此机制上,Grail 子网实现了 GRPO 风格的可验证后训练流程:矿工为同一题目生成多条推理路径,验证者依据正确性、推理链质量与 SAT 满足度评分,并将归一化结果写入链上,作为 TAO 权重。公开实验显示,该框架已将 Qwen2.5-1.5B 的 MATH 准确率从 12.7% 提升至 47.6%,证明其既能防作弊,也能显著强化模型能力。在 Covenant AI 的训练栈中,Grail 是去中心化 RLVR/RLAIF 的信任与执行基石,目前尚未正式主网上线。
Fraction AI:基于竞争的强化学习 RLFC
Fraction AI 的架构明确围绕 竞争强化学习(Reinforcement Learning from Competition, RLFC) 和游戏化数据标注构建 ,将传统 RLHF 的静态奖励与人工标注替换为开放、动态的竞争环境。代理在不同 Spaces 中对抗,其相对排名与 AI 法官评分共同构成实时奖励,使对齐过程演变为持续在线的多智能体博弈系统。
传统 RLHF 与 Fraction AI 的 RLFC 之间的核心差异:

RLFC 的核心价值在于奖励不再来自单一模型,而来自不断演化的对手与评估者,避免奖励模型被利用,并通过策略多样性防止生态陷入局部最优。Spaces 的结构决定博弈性质(零和或正和),在对抗与协作中推动复杂行为涌现。
在系统架构上,Fraction AI 将训练过程拆解为四个关键组件:
- Agents:基于开源 LLM 的轻量策略单元,通过 QLoRA 以差分权重扩展,低成本更新;
- Spaces:隔离的任务域环境,代理付费进入并以胜负获得奖励;
- AI Judges:以 RLAIF 构建的即时奖励层,提供可扩展、去中心化的评估;
- Proof-of-Learning:将策略更新绑定到具体竞争结果,确保训练过程可验证、防作弊。
Fraction AI 的本质是构建了一个人机协同的进化引擎。用户作为策略层的「元优化者」 (Meta-optimizer),通过提示工程(Prompt Engineering)和超参配置引导探索方向;而代理在微观的竞争中自动生成海量的高质量偏好数据对 (Preference Pairs)。这种模式让数据标注通过 「去信任化微调」 (Trustless Fine-tuning) 实现了商业闭环 。
强化学习 Web3 项目 架构比较

五. 总结与展望:强化学习 × Web3 的路径与机会
基于对上述前沿项目的解构分析,我们观察到:尽管各团队的切入点(算法、工程或市场)各异,但当强化学习(RL)与 Web3 结合时,其底层架构逻辑皆收敛为一个高度一致的「解耦 - 验证 - 激励」范式。这不仅是技术上的巧合,更是去中心化网络适配强化学习独特属性的必然结果。
强化学习通用架构特征:解决核心的物理限制与信任问题
- 推训物理分离 (Decoupling of Rollouts & Learning) —— 默认计算拓扑
- 通信稀疏、可并行的 Rollout 外包给全球消费级 GPU,高带宽的参数更新集中于少量训练节点,从 Prime Intellect 的异步 Actor–Learner 到 Gradient Echo 的双群架构皆如此。
- 验证驱动的信任层 (Verification-Driven Trust) —— 基础设施化
- 在无需许可的网络中,计算真实性必须通过数学与机制设计强制保障,代表实现包括 Gensyn 的 PoL、Prime Intellect 的 TOPLOC 与 Grail 的密码学验证。
- 代币化的激励闭环 (Tokenized Incentive Loop) —— 市场自我调节
- 算力供给、数据生成、验证排序与奖励分配形成闭环,通过奖励驱动参与、通过 Slash 抑制作弊,使网络在开放环境中依然保持稳定与持续演进。
差异化技术路径:一致架构下的不同「突破点」
尽管架构趋同,但各项目根据自身基因选择了不同的技术护城河:
- 算法突破派 (Nous Research):试图从数学底层解决分布式训练的根本矛盾(带宽瓶颈)。其 DisTrO 优化器旨在将梯度通信量压缩数千倍,目标是让家庭宽带也能跑得动大模型训练,这是对物理限制的「降维打击」。
- 系统工程派 (Prime Intellect, Gensyn, Gradient):侧重于构建下一代的「AI 运行时系统」。Prime Intellect 的 ShardCast 和 Gradient 的 Parallax 都是为了在现有的网络条件下,通过极致的工程手段压榨出最高的异构集群效率。
- 市场博弈派 (Bittensor, Fraction AI):专注奖励函数(Reward Function)的设计。通过设计精妙的评分机制,引导矿工自发寻找最优策略,来加速智能涌现。
优势、挑战与终局展望
在强化学习与 Web3 结合的范式下,系统级优势首先体现在 成本结构与治理结构的重写。
- 成本重塑:RL 后训练(Post-training)对采样(Rollout)的需求是无限的,Web3 能以极低成本调动全球长尾算力,这是中心化云厂商难以比拟的成本优势。
- 主权对齐 (Sovereign Alignment):打破大厂对 AI 价值观(Alignment)的垄断,社区可以通过 Token 投票决定模型「什么是好的回答」,实现 AI 治理的民主化。
与此同时,这一体系也面临两大结构性约束。
- 带宽墙 (Bandwidth Wall):尽管有 DisTrO 等创新,物理延迟仍限制了超大参数模型(70B+)的全量训练,目前 Web3 AI 更多局限于微调和推理。
- 古德哈特定律 (Reward Hacking):在高度激励的网络中,矿工极易「过拟合」奖励规则(刷分)而非提升真实智能。设计防作弊的鲁棒奖励函数是永恒的博弈。
- 恶意拜占庭式节点攻击 (BYZANTINE worker):通过对训练信号的主动操纵与投毒破坏模型收敛。核心不在于持续设计防作弊的奖励函数,而在于构建具备对抗性鲁棒性的机制。
强化学习与 Web3 的结合,本质是在重写「智能是如何被生产、对齐并分配价值」的机制。其演进路径可概括为三条互补方向:
- 去中心化推训网络:从算力矿机到策略网络,将并行且可验证的 Rollout 外包给全球长尾 GPU,短期聚焦可验证推理市场,中期演化为按任务聚类的强化学习子网;
- 偏好与奖励的资产化:从标注劳工到数据股权。 实现偏好与奖励的资产化,将高质量反馈与 Reward Model 变为可治理、可分配的数据资产,从「标注劳工」升级为「数据股权」
- 垂直领域的「小而美」进化:在结果可验证、收益可量化的垂直场景中孕育小而强的专用 RL Agents,如 DeFi 策略执行、代码生成,使策略改进与价值捕获直接绑定并有望跑赢通用闭源模型。
总体来看,强化学习 × Web3 的真正机会不在于复制一个去中心化版 OpenAI,而在于重写「智能生产关系」:让训练执行成为开放算力市场,让奖励与偏好成为可治理的链上资产,让智能带来的价值不再集中于平台,而在训练者、对齐者与使用者之间重新分配。

免责声明:本文在创作过程中借助了 ChatGPT-5 与 Gemini 3 的 AI 工具辅助完成,作者已尽力校对并确保信息真实与准确,但仍难免存在疏漏,敬请谅解。需特别提示的是,加密资产市场普遍存在项目基本面与二级市场价格表现背离的情况。本文内容仅用于信息整合与学术 / 研究交流,不构成任何投资建议,亦不应视为任何代币的买卖推荐。
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。












































