
合约分类是交易所、钱包、区块链浏览器、数据分析平台等的基石。
撰文:十四君
在智能合约领域,「以太坊虚拟机 EVM」以及其算法和数据结构就是第一性原理。
本文从合约为什么要分类出发,结合每个场景可能面对怎样的恶意攻击,最终给出一套达成相对安全的合约分类分析算法。
虽然技术含量较高,但亦可作为杂谈读物,一览去中心化系统间博弈的黑暗森林。
1、合约为什么要分类?
因为太重要了,可谓是交易所、钱包、区块链浏览器、数据分析平台等等 Dapp 的基石!
一笔交易之所以是 ERC20 转账,是因为他的行为符合 ERC20 标准,至少得有:
- 交易的状态是成功
- To 地址为某个符合 ERC20 标准的合约
- 调用了 Transfer 函数,其特点是该交易 CallData 的前 4 位为
0xa9059cbb - 执行后,在该 To 地址上发出了
transfer的事件
分类有误则交易行为会误判
以交易行为为基石,则 To 地址能否被准确分类则对其 CallData 的判断会有截然不然的结论。对 Dapp 而言,链上链下的信息沟通高度依赖于交易事件的监听,而同样的事件编码也只有在符合标准的合约中发出,才具有可信度。
分类有误则交易会误入黑洞
如果用户进行一笔 Token 转移,转入到某个合约中,如果该合约没有预设 Token 转出的函数方法,则资金会雷同于 Burn 一样被锁定,无法控制
且如今大量项目开始增加内置的钱包支持,要为用户管理钱包也就不可避免的,需要时刻从链上实时分类出最新部署的合约,是否能够吻合资产标准。
拓展阅读第 1 段:【合约解读】CryptoPunk 世界上最早的去中心化 NFT 交易市场
2、分类会有怎样的风险?
链上是一个没有身份没有法治的地方,你无法制止一笔正常的交易,哪怕他是恶意的。
他可以是冒充外婆的狼,做出多数符合你预期的外婆行为,但目的是进屋抢劫。
声明标准,但可能实质不符合
常见的分类方式是直接采用 EIP-165 标准,读取该地址是否支持 ERC20 等,当然,这是一个高效率的方法,但是毕竟合约是对方控制,所以终究是可以伪造出一份申明。
165 标准的查询,只是在链上有限的操作码中,用最低成本去防止资金转入黑洞的方法。
这也是为什么我们之前分析 NFT 的时候,特地提及标准中会有一类SafeTransferFrom的方法,其中Safe就是指代了采用 165 标准判断出对方声明自己具备了 NFT 的转移能力。
拓展阅读 第 2.2 段:【源码解读】你买的 NFT 到底是什么?
唯有从合约字节码出发,做源码层面的静态分析,从合约预期的行为出发才有更精准的可能性。
3、合约分类方案设计
接下来咱们将系统的分析整体方案,注意我们的目的是「精度」和「效率」两项核心指标。
要知道即使方向是对的,但要抵达大洋的彼岸路途也并不明朗,要做字节码分析的第一站是获取代码。
3.1、如何获取到代码?
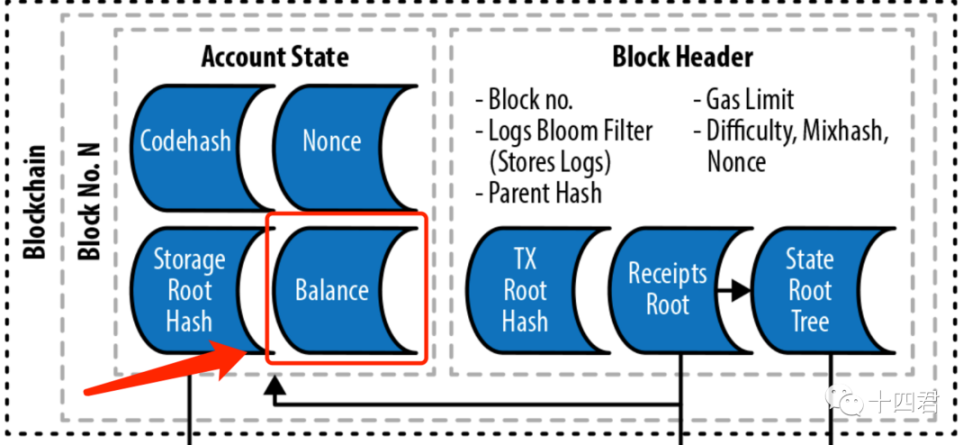
从上链后的角度讲有getCode,一个 RPC 方法,可以从链上指定的地址里获取到字节码,单论读取的话这是非常快捷的,因为从 EVM 的账号结构中就把 codeHash 放在最顶端的位置。
但是这个方法等于是单独对某个地址做获取,想要进一步提升精度和效率呢?
如果是部署合约的交易,如何在其刚执行完甚至他还在内存池中便获取部署的代码?
如果该笔交易是合约工厂的模式,则交易的 Calldata 里是否存在源码呢?
最后的我的方式是,是分类进行一种类似筛子的模式
- 对于非合约部署的交易,则直接用
getCode获取其中涉及的地址进行分类, - 对于最新内存池的交易,筛选出 to 地址为空的交易,其 CallData 则是带有构造函数的源代码
- 对于合约工厂模式的交易,由于其中可能是合约部署出的合约再循环调用其他合约来执行部署,则递归的去分析该笔交易的子交易,记录每个 type 为
CREATE或者为CREATE2的 Call。
我做了个 demo 实现的时候,发现还好现在 rpc 的版本比较高,因为整个过程最难的便是执行 3 的时候,如何递归找到指定 type 的 call,最底层的方式是通过 opcode 还原上下文,我吃了一惊!
还好现在的 geth 版本里有debug_traceTransaction 方法,他可以帮助解决在通过 opcode 操作码中梳理每一个 call 的上下文信息,整理出核心的字段。
最终可以对多种部署模式的(直接部署,工厂模式单部署,工厂模式批量部署)的原始字节码都获取到。
3.2、如何从代码分类?
最最简单但不安全的方式,是把 code 直接做字符串匹配,以 ERC20 为例符合标准的函数则有

在函数名之后的,则是该函数的函数签名,之前在分析的时候提及,交易都是依赖匹配 callData 的前 4 位找到目标函数的,拓展阅读:
所以合约字节码里必然存储有这 6 个函数的签名。
当然,这种方法非常快捷 6 个都查到就完事的,但不安全的因素则是,如果我采用 solidity 合约中,单独设计一个变量,存储值为0x18160ddd 那么他也会将认为我有了这个函数。
3.3、准确率提升 1- 反编译
那进一步的准确方法则是做 Opcode 的反编译!反编译则是将获取到的字节码转到操作码的过程,更高级的反编译则是再转成伪代码,更利于人的阅读,这次我们用不上,反编译的方法列于文末的附录中。
solidity(高级语言)->bytecode( 字节码 )->opcode( 操作码 )
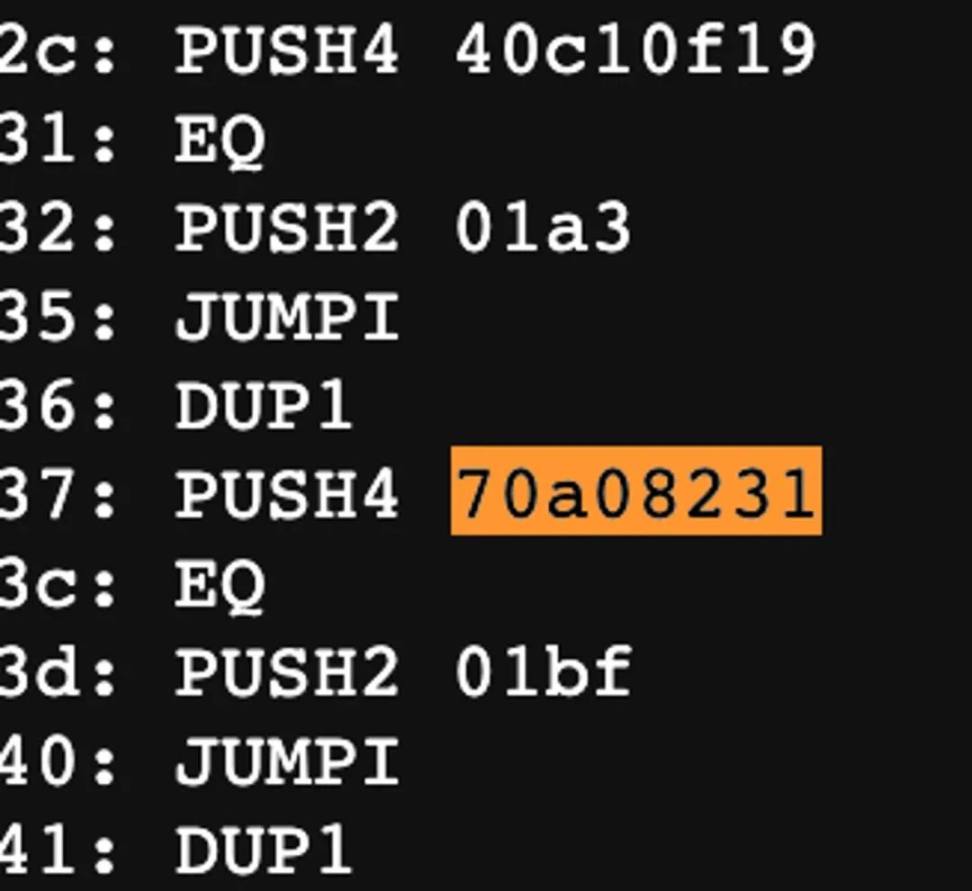
我们就可以清晰的发现一个特征,函数签名都会被PUSH4 这个操作码所执行,所以进一步的方法则是从全文中提取 PUSH4 后的内容,与函数标准做匹配。
我也简单做了下性能实验,不得不说 Go 语言的效率很强大,1W 次反编译只需要 220ms。
接下来的内容会有一定难度。
3.4、准确率提升 2- 找代码块
上文中准确率有所提升但还不够,因为是全文搜索PUSH4的,因为我们仍然可以构建一个变量,是byte4的类型,这样一来也会触发PUSH4的指令。
在我苦恼的时候,想到一些开源项目的实现,ETL 是一个读取链上数据做分析的工具,其中会解析出 ERC20、721 的转移单独成表,所以必然具备分类合约的能力。
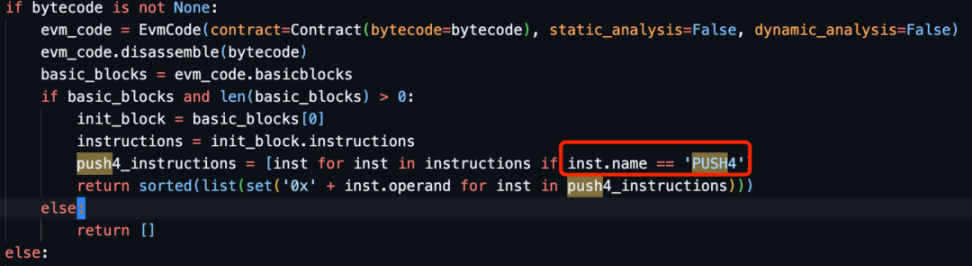
分析下来,可以发现他是基于代码块的分类,只处理第一个basic_blocks[0]里的push4指令
那问题来到了,如何准确判断代码块了
代码块的概念源于REVERT + JUMPDEST 这 2 个连续的操作码,这里必然需要连续的 2 个,因为在整个函数选取器的 opcode 区间里,如果函数数量过多,则会出现翻页的逻辑,那也会出现JUMPDEST 这个指令。

3.5、准确率提升 3- 找函数选择器
函数选择器的作用是,读取该笔交易的 Calldata 的前 4 位字节,并与代码中预设有的合约函数签名进行匹配,协助指令跳转到存储了该函数方法指定的内存位置。
让我们尝试一个最小的模拟执行
这部分是两个函数的选择器store(uint 256) 和retrieve(),可算出签名是2e64cec1,6057361d
60003560e01c80632e64cec11461003b5780636057361d1461005957
进行反编译后,则会得到如下的操作码串,可以说分两个部分
第一部分:
在编译器中在合约中仅函数选择器部分会去获取到 callData 的内容,寓意是获取其 CallData 的函数调用签名,注释如下图。

我们可以通过模拟 EVM 的内存池变化来看看效果
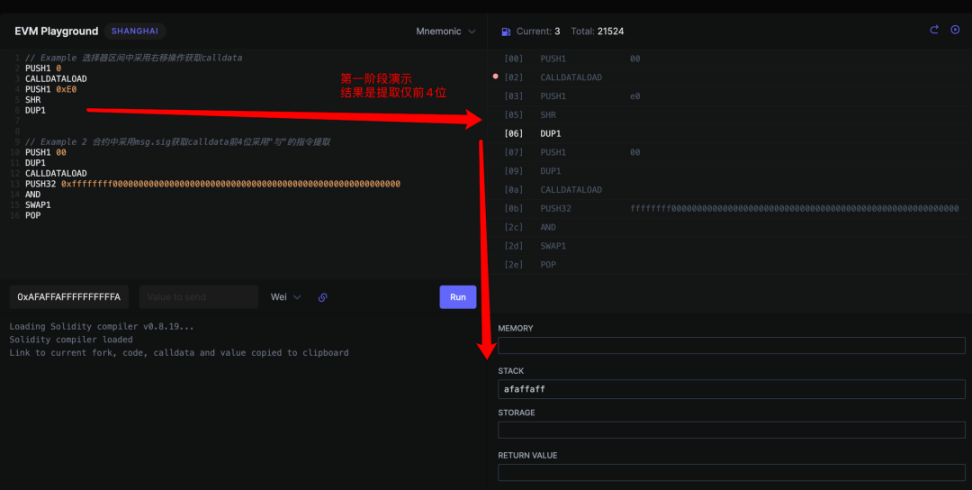
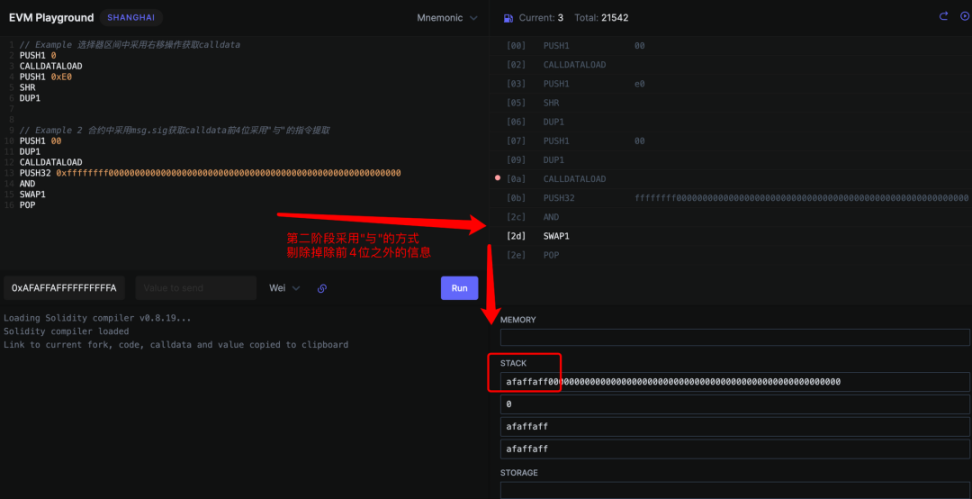
第二部分:
判断是否与选择器的值匹配的过程
- 将 retrieve() 的 4 字节函数签名 (0x2e64cec1) 传入 stack 上,
- EQ 操作码从 stack 区弹出 2 个变量,即 0x2e64cec1 和 0x6057361d,并检查它们是否相等
- PUSH2 将 2 个字节的数据 ( 这里为 0x003b,十进制为 59) 传入 stack,stack 区有一个叫做程序计数器的东西,它规定了下一个执行命令在字节码中的位置。这里我们设置 59,因为那是 retrieve() 字节码的起始位置
- JUMPI 代表「如果...,则跳转至...」,它从 stack 中弹出 2 个值作为输入,如果条件为真,程序计数器将被更新至 59。
这就是 EVM 是如何根据合约中的函数调用,来确定它需要执行的函数字节码的位置的原理。
实际上,这只是一组简单的「if 语句」,用于合约中的每个函数以及它们的跳转位置。

4、方案总结
整体简述如下
- 每个合约地址可以通过 rpc getcode 或者debug_traceTransaction,获取到部署后的bytecode ,采用 GO 中 VM 和 ASM 库,反编译后即获取到opcode
- 合约在
EVM运行原理中,会有以下特征 - 采用REVERT+JUMPDEST这 2 个连续的
opcode作为代码块的区分 - 合约必然具备函数选择器的功能,该功能也必然在第一个代码块上
- 函数选择器中,其函数方法均采用PUSH4作为
opcode, - 该选择器所包含的 opcode 中,会出现连续的PUSH1 00; CALLDATALOAD; PUSH1 e0; SHR; DUP1,核心功能是加载 callDate 数据并进行位移操作,从合约功能上其他语法不会产生
- 对应的函数签名在
eip中定义,并且有必选和可选的明确说明
4.1、唯一性证明
走到这里我们就可以说,基本实现高效率,高准确率的合约分析方法了,当然既然已经严谨了这么久,不妨再严谨一些,我们上文方案里中基于 REVER+JUMPDEST 来做代码块的区分,结合其中必然的 CallDate 加载和位移来做唯一性判断,那是否存在,我可以用 solidity 合约也实现出类似的操作码序列呢?
我做了下对照实验,从solidity语法层面虽然亦有msg.sig等获取CallData的方法,但编译后其opcode的实现方法不同
5、总结
洋洋洒洒这么分析下来,3 天时间就过去了。
虽然非常的细致,虽然日常中会遇到合约采用byte4来恶意混淆自己是否符合标准的合约可能是九牛一毛。
所以,实际上这 3 天投入分析的 ROI 是非常低的。但是在无尽的时间长河里,概率再小的事情,也终将发生。
怀揣不信任原则才能在 web3 的世界里,走的更远。
今天有好友问我一个很有思考深度的话题,作为产业 KOL 的终局是什么?你的商业模式是什么?
虽然我知道技术的文章,总是流量惨淡,但流量本就不是目的,我希望始终都在最初的愿景上:
💡 以技术的视角,洞察产业发展的关键变化,分享产业发展中的过往经验与未来机会,为新时代的建设者提供差异化的帮助。
附录
如需 opcode 样例以及 Go 进行反编译的样例代码,可公众号后台回复「合约分类」获取。
依赖库:
https://pkg.go.dev/github.com/ethereum/go-ethereum@v1.11.6/core/asm#Compiler.Feed
https://pkg.go.dev/github.com/ethereum/go-ethereum@v1.11.6/core/vm
原理解析:
https://whileydave.com/2023/01/04/disassembling-evm-bytecode-the-basics/
https://yanniss.github.io/elipmoc-oopsla22.pdf
https://yanniss.github.io/gigahorse-icse19.pdf
https://www.evm.codes/?fork=shanghai
https://learnblockchain.cn/article/4800
https://learnblockchain.cn/article/3647
开源项目源码参考:
https://github.com/blockchain-etl/ethereum-etl/blob/2da9d050f4ae4fa4e818bbfb22d5cfb5234b2e29/ethereumetl/service/eth_contract_service.py#L29-L43
https://github.com/ethereum/evmdasmhttps://github.com/tintinweb/ethereum-dasm/blob/master/ethereum_dasm/evmdasm.py#L342
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。


