现代大语言模型训练数据集的奥秘何在?
2023-03-06 23:13
对于训练当代 Transformer 大型语言模型的数据集而言,本文可能是最全面的整合分析内容(截止 2022 年初)。在主要数据源不透明的情况下,本次研究主要从二级和三级来源收集数据,并经常需要假定来确定最终估计值。随着研究人员要处理千万亿个 token(1,000 万亿)和数千 TB 的数据(1,000TB),确保详细披露数据集组成的文档变得越来越重要。
随着语言模型不断发展并更广泛地渗透到人们的生活中,确保数据集的详细信息公开透明、所有人都可访问且易于理解是有用、紧迫和必要的。
注:本文原文标题为《ChatGPT 数据集之谜》,论文经授权后由一流科技 OneFlow 编译发布,译文转载请联系 OneFlow 获得授权
一个问题:ChatGPT 的核心算法 Transformer 最初是由 Google 提出的,并且在大模型技术上的积累可以说不弱于 OpenAI,当然他们也不缺算力和数据,但为什么依然会被 ChatGPT 打的措手不及?
其实,对互联网大厂之外的团队来说,剩下最大的挑战在于高质量训练数据集。本文作者整理分析了 2018 年到 2022 年初从 GPT-1 到 Gopher 的相关大型语言模型的所有数据集相关信息,希望帮助有志于开发“类 ChatGPT”模型的团队少走一步弯路。
一些研究人员的报告称,通用人工智能(AGI)可能是从我们当前的语言模型技术进行演进[1],预训练 Transformer 语言模型为 AGI 的发展铺平了道路。虽然模型训练数据集日渐增大,但缺乏基本指标文档,包括数据集大小、数据集 token 数量和具体的内容细节。尽管业内提出了数据集组成和整理文档的标准[2],但几乎所有重点研究实验室在揭示模型训练数据集细节这方面都做得不够。这里整合的研究涵盖了 2018 年到 2022 年初从 GPT-1 到 Gopher 的精选语言模型的所有数据集(包括主要数据集:Wikipedia 和 Common Crawl)的综合视图。
图 1. 主要数据集大小的可视化汇总。未加权大小,以 GB 为单位。2018 年以来,大语言模型的开发和生产使用呈现出爆炸式增长。一些重点研究实验室报告称,公众对大语言模型的使用率达到了惊人高度。2021 年 3 月,OpenAI 宣布[3]其 GPT-3 语言模型被“超过 300 个应用程序使用,平均每天能够生成 45 亿个词”,也就是说仅单个模型每分钟就能生成 310 万词的新内容。值得注意的是,这些语言模型甚至还没有被完全理解,斯坦福大学的研究人员[4]最近坦言,“目前我们对这些模型还缺乏认知,还不太了解这些模型的运转模式、不知道模型何时会失效,更不知道这些模型的突现性(emergent properties)能产生什么效果”。随着新型 AI 技术的快速发展,模型训练数据集的相关文档质量有所下降。模型内部到底有什么秘密?它们又是如何组建的?本文综合整理并分析了现代大型语言模型的训练数据集。因为这方面的原始文献并不对外公开,所以本文搜集整合了二、三级研究资料,在必要的时候本文会采用假设的方式来推算最终结果。在本文中,我们会将原始论文中已经明确的特定细节(例如 token 数量或数据集大小)归类为“公开的(disclosed)”数据,并作加粗处理。多数情况下,适当地参考二、三级文献,并采用假设的方式来确定最终结果是很有必要的。在这些情况下,token 数量和数据集大小等细节是“确定的(determined)”,并以斜体标记。模型数据集可分为六类,分别是:维基百科、书籍、期刊、Reddit 链接、Common Crawl 和其他数据集。表 1. 主要数据集大小汇总。以 GB 为单位。公开的数据以粗体表示。确定的数据以斜体表示。仅原始训练数据集大小。 维基百科是一个免费的多语言协作在线百科全书,由超过 300,000 名志愿者组成的社区编写和维护。截至 2022 年 4 月,英文版维基百科中有超过 640 万篇文章,包含超 40 亿个词[5]。维基百科中的文本很有价值,因为它被严格引用,以说明性文字形式写成,并且跨越多种语言和领域。一般来说,重点研究实验室会首先选取它的纯英文过滤版作为数据集。 故事型书籍由小说和非小说两大类组成,主要用于训练模型的故事讲述能力和反应能力,数据集包括 Project Gutenberg 和 Smashwords (Toronto BookCorpus/BookCorpus) 等。 预印本和已发表期刊中的论文为数据集提供了坚实而严谨的基础,因为学术写作通常来说更有条理、理性和细致。这类数据集包括 ArXiv 和美国国家卫生研究院等。 WebText 是一个大型数据集,它的数据是从社交媒体平台 Reddit 所有出站链接网络中爬取的,每个链接至少有三个赞,代表了流行内容的风向标,对输出优质链接和后续文本数据具有指导作用。1.5. Common Crawl
Common Crawl 是 2008 年至今的一个网站抓取的大型数据集,数据包含原始网页、元数据和文本提取,它的文本来自不同语言、不同领域。重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。不同于上述类别,这类数据集由 GitHub 等代码数据集、StackExchange 等对话论坛和视频字幕数据集组成。2
常用数据集
2019 年以来,大多数基于 Transformer 的大型语言模型 (LLM) 都依赖于英文维基百科和 Common Crawl 的大型数据集。在本节中,我们参考了 Jesse Dodge 和 AllenAI(AI2)[8]团队的综合分析,按类别对英文维基百科作了高级概述,并在 Common Crawl 数据集[7]的基础上,用谷歌 C4[6] (Colossal Clean Crawled Corpus) 在 Common Crawl 中提供了顶级域(domains)。 下面按类别[9]列出了维基百科的详细信息,涵盖了 2015 年抽样的 1001 篇随机文章,研究人员注意到随时间推移文章传播的稳定性。假设一个 11.4GB、经过清理和过滤的维基百科英文版有 30 亿 token,我们就可以确定类别大小和 token。表 2. 英文维基百科数据集类别。公开的数据以粗体表示。确定的数据以斜体表示。基于 AllenAI (AI2) 的 C4 论文,我们可以确定,过滤后的英文 C4 数据集的每个域的 token 数和总体百分比,该数据集为 305GB,其中 token 数为 1560 亿。表 3. C4:前 23 个域(不包括维基百科)。公开的数据以粗体表示,确定的数据以斜体表示。
3
GPT-1 数据集
2018 年,OpenAI 发布了 1.17 亿参数的 GPT-1。在论文中,OpenAI 并没有公布模型训练数据集的来源和内容[10],另外,论文误将‘BookCorpus’拼写成了‘BooksCorpus’。BookCorpus 以作家未出版的免费书籍为基础,这些书籍来自于 Smashwords,这是一个自称为“世界上最大的独立电子书分销商” 的电子书网站。这个数据集也被称为 Toronto BookCorpus。经过几次重构之后,BookCorpus 数据集的最终大小确定为 4.6GB[11]。 2021 年,经过全面的回顾性分析,BookCorpus 数据集对按流派分组的书籍数量和各类书籍百分比进行了更正[12]。数据集中有关书籍类型的更多详细信息如下:表 4. BookCorpus 书籍类型。公开的数据以粗体表示,确定的数据以斜体表示。 在随后的数据集重构中,BookCorpus 数据集进一步过滤掉了书籍中的“吸血鬼”类别、降低了言情类书籍的百分比、增加了“历史”类书籍,增加了收集的书籍数量。表 5.GPT-1 数据集总结。以 GB 为单位。公开的数据以粗体表示,确定的数据以斜体表示。4
2019 年,OpenAI 发布了拥有 15 亿参数的语言模型 GPT-2。GPT-2 论文阐明了所用训练数据集的大小[13],不过并未说明其内容。而 GPT-2 模型卡(model card)(在 GPT-2 GitHub 仓库中)说明了模型内容[14]。 我们可以从 GPT-3 论文中得到 token 数量,该论文使用了 WebText 扩展版本来表示 190 亿 token。据推测,2020 年推出的 WebText 扩展版本拥有 12 个月的额外数据(additional data),因此它可能比 2019 年推出的 GPT-2 版本大 25% 左右[15]。GPT-2 最终的 token 数量确定为 150 亿左右。 如 GPT-2 论文所述,假设模型卡显示链接数时,每个链接都可以被 4500 万链接总数所除,那 WebText 的内容在数据集中所占的百分比的详细信息就可以确定。然后可以使用确定的 150 亿 token 数量来查找每个域的 token 数量。请注意,在可用的前 1,000 个域中,此处仅显示前 50 个域。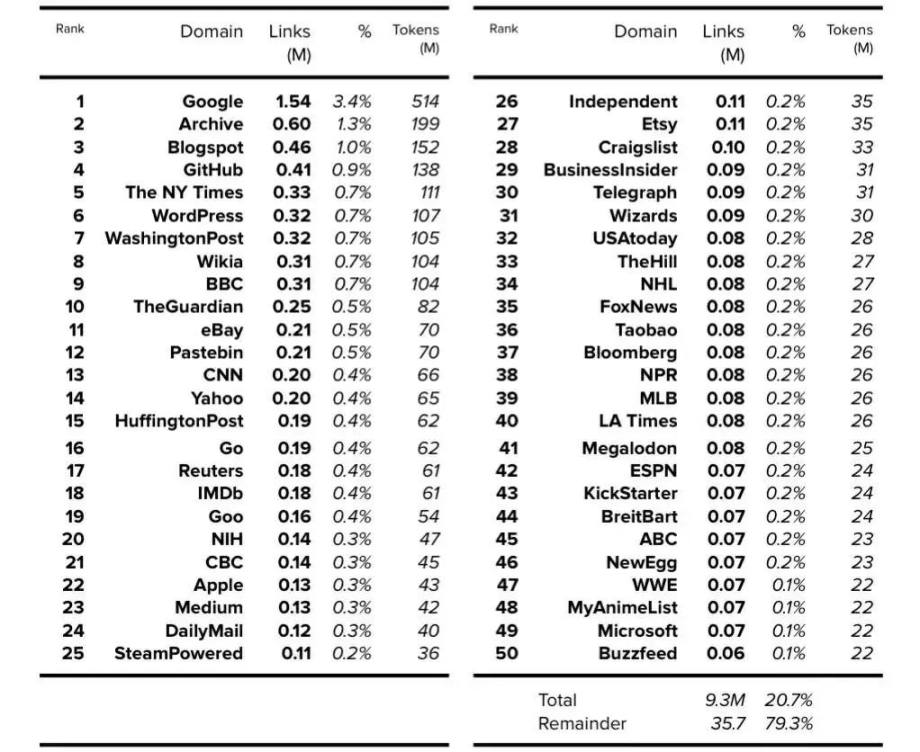
表 6. WebText: 前 50 个域。 公开的数据以粗体表示,确定的数据以斜体表示。表 7. GPT-2 数据集总结。 公开的数据以粗体表示,确定的数据以斜体表示。5
GPT-3 模型由 OpenAI 于 2020 年发布。论文阐明了所用训练数据集的 token 数量[16],但训练数据集的内容和大小尚不清楚(Common Crawl 的数据集大小除外[17])表 8. GPT-3 数据集。 公开的数据以粗体表示,确定的数据以斜体表示。5.1. GPT-3:关于 Books1 和 Books2 数据集的分析特别值得关注的是,在 OpenAI 的 GPT-3 论文中,并未公开 Books1 数据集(120 亿 token)和 Books2 数据集(550 亿 token)的大小和来源。关于这两个数据集的来源人们提出了几个假设,包括来自 LibGen18 和 Sci-Hub 的类似数据集,不过这两个数据集常以 TB 为计,大到无法匹配。 GPT-3 使用的 Books1 数据集不可能与 GPT-1 使用的 BookCorpus 数据集相同,原因在于 Books1 的数据集更大,达 120 亿 token。在一篇引用的论文[19]中就提及 GPT-1 使用的 BookCorpus 数据集拥有 9.848 亿个词,但这可能只相当于 13 亿 token(984.8 字 x 1.3 字的 token 乘数)。 通过标准化项目古腾堡语料库(SPGC),Books1 有可能与古腾堡项目保持一致性。SPGC 是一种开放式科学方法,被用于古腾堡项目完整的 PG 数据的精选(curated)版本。SPGC 包含 120 亿个 token[20],大约为 21GB[21]。Books2(550 亿 token)可能与 Bibliotik 保持一致,并由 EleutherA 收集该来源的数据,组成数据集,使其成为 The Pile v1 的一部分。Bibliotik 版本为 100.96GB[22],其确定的 token 数仅为 250 亿,低于 Books2 公开的 550 亿。然而,使用 SPGC 的‘每字节 token 数’比率(大约为 1:1.75),Bibliotik 的 token 数和大小将更接近于 Books2。附录 A 概述了使用 Wikipedia + CommonCrawl + WebText 数据集的顶级资源列表。GPT-3 模型的最终数据集总结分析如下:表 9.GPT-3 数据集总结。公开的数据以粗体表示,确定的数据以斜体表示。6
The Pile v1(GPT-J 和 GPT-NeoX-20B)数据集The Pile v1 数据集由 EleutherAI 于 2021 年发布,该数据集已被用于训练包括 GPT-J、GPT-NeoX-20B 在内的多种模型,并作为包括 MT-NLG 在内的其他模型的部分数据集。The Pile v1 论文阐明了所用训练数据集的来源和大小。随着 token 数量的增加,The Pile v1 论文应被用作未来数据集文档的黄金标准。 有关 token 数量的更多详情,可以使用本文提供的信息来确定,参见表 1(大小以 GB 为单位)和表 7(token/ 每字节)[23]。表 10. The Pile v1 数据集。公开的数据以粗体表示,确定的数据以斜体表示。6.1. The Pile v1 分组数据集(Grouped Datasets)为了确定如‘Books’、‘Journals’和‘CC’这类数据集的大小,笔者对数据集进行了分组,如下表所示。
表 11. The Pile v1 分组数据集(不包括 Wikipedia、CC 和 WebText)。公开的数据以粗体表示,确定的以斜体表示。The Pile v1 数据集与 GPT-J 和 GPT-NeoX-20B 模型的最终数据集总结分析如下:表 12. Pile v1 数据集总结。 公开的数据以粗体表示,确定的数据以斜体表示。7
Megatron-11B 和 RoBERTa 数据集2019 年,Meta AI( 当时称之为 Facebook AI) 和华盛顿大学联合发布了拥有 1.25 亿参数的 RoBERTa 模型。次年,Meta AI 发布了拥有 110 亿参数的 Megatron-11B 模型。Megatron-11B 使用的训练数据集与 RoBERTa 相同。RoBERTa[24]论文阐明了所用训练数据集的内容,不过必须参考引用的论文 (BERT[25]和 toryes[26]) 来确定最终的数据集大小。BookCorpus: 确定的数据集为 4.6GB,如上面的 GPT-1 部分所示。维基百科:公开的数据集为“16GB(BookCorpus 加上英文维基百科)”。在减去 BookCorpus 数据集(4.6GB,如上面的 GPT-1 部分所述)后,维基百科数据集确定为 11.4GB。CC-News:(经过滤后)公开的数据集为 76GB。OpenWebText: 公开的数据集为 38GB。Stories: 公开的数据集为 31GB。请注意,此数据集是“基于常识推理任务问题”的 Common Crawl 内容,不属于本文的‘Books’类别。相反,将 Stories 与 CC-News 数据集(76GB)相结合,Common Crawl 的总数据集则为 107GB。7.1. Megatron-11B 和 RoBERTa 的数据集总结Megatron-11B 和 RoBERTa 最终的数据集总结分析如下:表 13. Megatron-11B 和 RoBERTa 的数据集总结。 公示的数据以粗体表示,确定的数据以斜体表示。8
2021 年,英伟达和微软发布了拥有 5300 亿参数的语言模型 MT-NLG。MT-NLG 是微软 Turing NLG(拥有 170 亿参数)和英伟达 Megatron-LM(拥有 83 亿参数)的“继任者”。MT-NLG 论文阐明了所用训练数据集的来源和 token 数量,不过没有明确指出数据集的大小。 如前所述,有关数据集大小的更多详情,可以使用 The Pile v1 论文中提供的信息来确定。虽然使用的组件相同,但注意的是,MT-NLG 和 The Pile v1 中报告的组件大小却各不相同,这是由于来自 Eleuther AI (The Pile v1 数据集 ) 和 Microsoft/NVIDIA (MT-NLG 模型 ) 的研究人员采用了不同的数据过滤和去重方法。8.1. MT-NLG 中的 Common Crawl 数据集Pile-CC:公开的数据集为 498 亿 token,确定的数据为 227.12GB 左右,参见上述 Pile v1 部分CC-2020-50: 公开的数据集为 687 亿 token,假设 token 的每字节率(per byte rate)为 0.25 TpB=274.8GB。CC-2021-04:公开的数据集为 826 亿 token,假设 token 的每字节率为 0.25 TpB=330.4GBRealNews(来自 RoBERTa/Megatron-11B):显示为 219 亿 token。根据 RealNews 论文[27],数据集确定为 120GB。CC-Stories( 来自 RoBERTa/Megatron-11B):公开的数据集为 53 亿 token,如上述 RoBERTa 部分所示,数据集确定为 31GB。根据以上来源,可确认 Common Crawl 的总数据量为 983.32GB,共计 2283 亿 token。8.2. MT-NLG 分组数据集(Grouped Datasets)表 14. MT-NLG 分组数据集。公开的数据以粗体表示,确定的数据以斜体表示。表 15. MT-NLG 数据集总结。 公示的数据以粗体表示,确定的数据以斜体表示。9
Gopher 模型由 DeepMind 于 2021 年发布,有 2800 亿参数。该论文清楚地说明了所使用训练数据集所包含的高级 token 数量和大小[28],但没有说明详细内容。表 16. 公开的 Gopher 数据集 (MassiveText)。公开的数据以粗体表述,确定的数据以斜体表示。 有趣的是,据 Gopher 论文披露:其 Books 数据集中包含一些超过 500 年历史(1500-2008)的书籍。 DeepMind 于 2014 年被谷歌收购,并在创建 MassiveText 时获得了海量数据。虽然 Gopher 论文中没有进一步详细描述 MassiveWeb,但第 44 页附录中的表 A3b 注明了 MassiveWeb 中出现的前 20 个域[29]。根据披露的每个域所占的百分比,我们可以使用 MassiveWeb 的总 token 数(5060 亿 token)和总原始大小(1900GB)来确定每个域的 token 数量和大小。表 17. MassiveWeb:前 20 个域。公开的数据以粗体表示,确定的数据以斜体表示。维基百科数据集的总规模很难确定。在 Gopher 论文中,研究人员指出维基百科没有进行数据去重[30]。然而,论文中列出的不同大小数据集(12.5GB MassiveWeb Wikipedia 与 1GB MassiveText Wikipedia)可能是由于失误而造成的,误将“10GB”写成了“1GB”。无论如何,本文仅使用 MassiveWeb 数据集版本 (12.5GB)。 Gopher 数据集的组成部分不包括 Reddit 外链的 WebText 数据集。为了清楚起见,尽管 Reddit 是 MassiveWeb 中的顶级域,但该数据集仅抓取 Reddit 域内的 Reddit 链接。根据定义,WebText[31]由“所有 Reddit 的外链”组成(即指向 Reddit 域外的链接)。 MassiveWeb 被认为是 MassiveText 的子组件,并被集成到 Gopher 的数据集汇总中,其分组基于以下列出的可用信息:表 18. Gopher 分组数据集。公开的数据以粗体表示,确定的数据以斜体表示。Gopher 是本文中最大的数据集,大小为 10.5TB。Gopher 模型的最终数据集总结分析为:表 19. Gopher 数据集总结。公开的数据以粗体表示,确定的数据以斜体表示。10
对于训练当代 Transformer 大型语言模型的数据集而言,这可能是最全面的整合分析内容(截止 2022 年初)。在主要数据源不透明的情况下,本次研究主要从二级和三级来源收集数据,并经常需要假定来确定最终估计值。随着研究人员要处理千万亿个 token(1,000 万亿)和数千 TB 的数据(1,000TB),确保详细披露数据集组成的文档变得越来越重要。特别值得关注的是,基于大型语言模型的强大 AI 系统产生的冗长而匿名的输出正在迅速发展,其中许多数据集的细节内容几乎没有文档说明。强烈建议研究人员使用突出显示的“数据集的数据表(Datasheet for Datasets)”论文中提供的模板,并在记录数据集时使用最佳实践论文(即 Pile v1 论文,包括 token 数量)。数据集大小(GB)、token 数量(B)、来源、分组和其他详细信息指标均应完整记录和发布。 随着语言模型不断发展并更广泛地渗透到人们的生活中,确保数据集的详细信息公开透明、所有人都可访问且易于理解是有用、紧迫和必要的。考虑到简洁和可读性,本文使用了脚注而非文本 / 括弧式引文。主要参考文献如下,或者参见http://lifearchitect.ai/papers/,获取大语言模型领域的主要基础论文。以下论文按本文顺序显示。- Datasheets for Datasets Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J., Wallach, H., Daumé III, H., & Crawford, K. (2018). Datasheets for Datasets. https://arxiv.org/abs/1803.09010
- GPT-1 paper Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI. https://cdn.openai.com/research-covers/language-unsupervised/language_understan ding_paper.pdf
- GPT-2 paper Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI. https://cdn.openai.com/better-language-models/language_models_are_unsupervised _multitask_learners.pdf
- GPT-3 paper Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., & Dhariwal, P. et al. (2020). OpenAI. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
- The Pile v1 paper Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., & Foster, C. et al. (2021). The Pile: An 800GB Dataset of Diverse Text for Language Modeling.
- EleutherAI. https://arxiv.org/abs/2101.00027
- GPT-J announcement Komatsuzak, A., Wang, B. (2021). GPT-J-6B: 6B JAX-Based Transformer. https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
- GPT-NeoX-20B paper Black, S., Biderman, S., Hallahan, E. et al. (2022). EleutherAI. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
- RoBERTa paper Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., & Chen, D. et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. Meta AI. https://arxiv.org/abs/1907.11692
- MT-NLG paper Smith, S., Patwary, M., Norick, B., LeGresley, P., Rajbhandari, S., & Casper, J. et al. (2021). Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. Microsoft/NVIDIA. https://arxiv.org/abs/2201.11990
- Gopher paper Rae, J., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., & Song, F. et al. (2021). Scaling Language Models: Methods, Analysis & Insights from Training Gopher. DeepMind. https://arxiv.org/abs/2112.11446
- Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3)
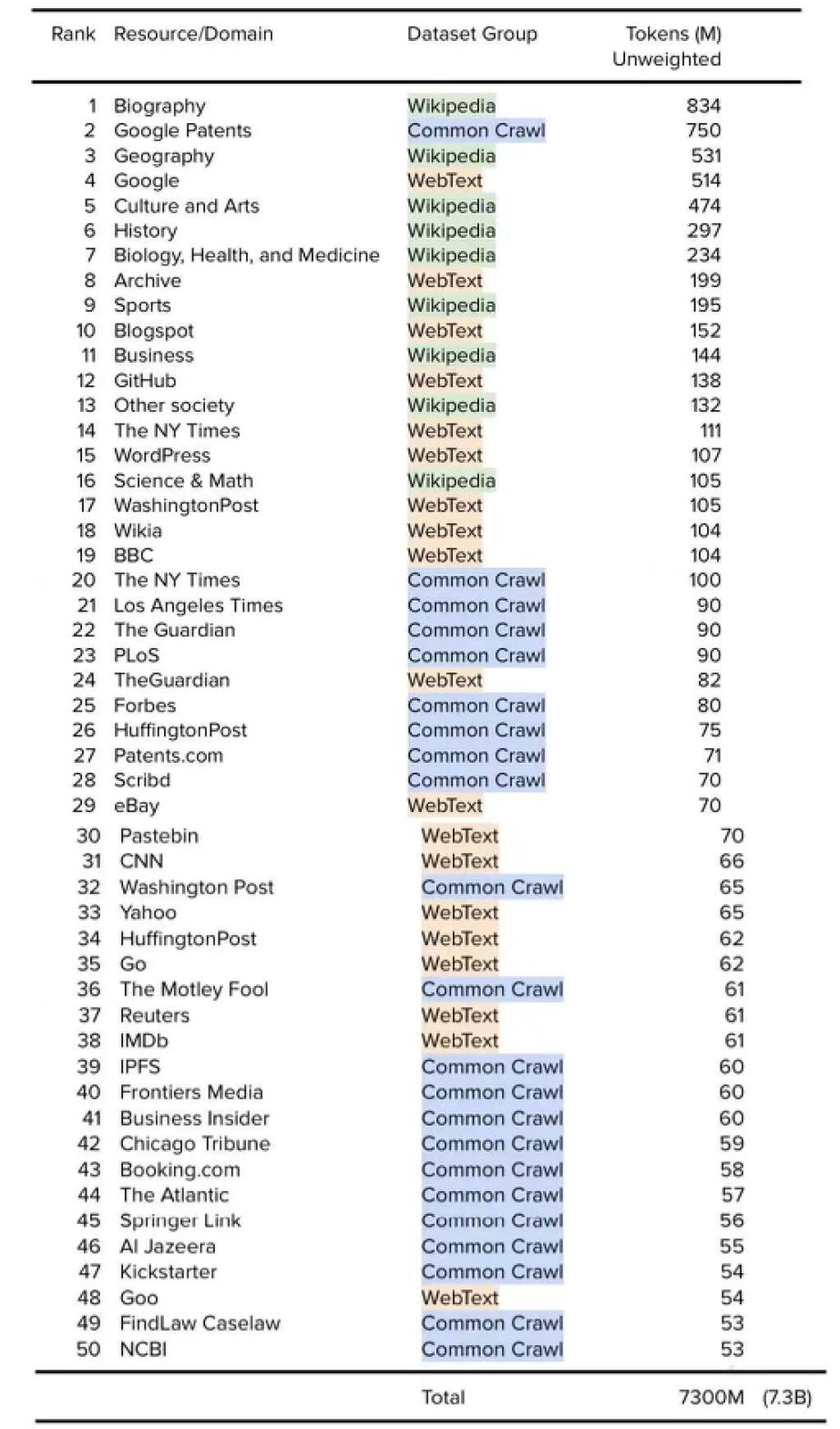
附录 A:前 50 个资源:Wikipedia + CC + WebText(即 GPT-3)基于本文内容,尤其是每个数据集中每个资源的 token 数量,我们可以对将 Wikipedia + Common Crawl + WebText 数据集的组合,作为其整体训练数据集的一部分模型进行资源或域的排序。为清楚起见,这包括以下模型:OpenAI GPT-3、EleutherAI GPT-J、EleutherAI GPT-NeoX-20B、Meta AI Megatron-11B 和 RoBERTA,以及 Microsoft/NVIDIA MT-NLG 等。请注意,展示的排名基于数据集中可用的未加权总 token,每个数据集的主观权重由研究人员在模型预训练之前计算得出。其中有一些重复(例如,《纽约时报》既出现在有 1.11 亿 token 的 WebText 中,也出现在过滤后有 1 亿 token 的 Common Crawl 中)。
1. GPT-NeoX-20B paper: pp11, section 6 http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf2. Datasheet for Datasets paper: https://arxiv.org/abs/1803.090103. OpenAI blog: https://openai.com/blog/gpt-3-apps/4. On the Opportunities and Risks of Foundation Models: https://arxiv.org/abs/2108.072585. Size of Wikipedia: https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia6. C4 dataset: https://www.tensorflow.org/datasets/catalog/c47. Common Crawl website: https://commoncrawl.org/8. C4 paper: https://arxiv.org/abs/2104.08758 pp2, Figure 1 right9. Wikipedia categories: https://en.wikipedia.org/wiki/User:Smallbones/1000_random_results: “维基百科涵盖哪些主题?覆盖范围是否随时间变化?使用 2015 年 12 月抽取的 1001 篇随机文章对这些问题和类似问题进行了查验...随着时间推移,这些比例相当稳定...传记(27.8%),地理(17.7%),文化和艺术(15.8%),历史(9.9%),生物学、健康和医学(7.8%),体育(6.5%),商业(4.8%),其他社会(4.4%),科学与数学(3.5%),教育(1.8%)。”10. GPT-1 paper: pp4 “We use the BooksCorpus dataset for training the language model.”11. https://huggingface.co/datasets/bookcorpus: “Size of the generated dataset: 4629.00 MB”12. BookCorpus Retrospective Datasheet paper: pp9 https://arxiv.org/abs/2105.0524113. GPT-2 paper: pp3 “我们从社交媒体平台 Reddit 中抓取了至少有 3 个 karma 的所有出站链接。这可以被认为是一个启发式指标,用于判断其他用户是否觉得该链接有趣、有教育意义或只是有趣……WebText 包含这 4500 万个链接的文本子集……其中不包括 2017 年 12 月之后创建的链接。经过去重和一些基于启发式的清理后,其中包含大约超过 800 万个文档,总共 40GB 文本。我们从 WebText 中移除了所有维基百科文档...”14. GPT-2 model card: https://github.com/openai/gpt-2/blob/master/model_card.md: “我们已经发布了 WebText 中出现的前 1,000 个域及其频率的列表。WebText 中排名前 15 位的域是:Google、Archive、Blogspot、GitHub、纽约时报、Wordpress、华盛顿邮报、维基亚、BBC、卫报、eBay、Pastebin、CNN、雅虎和赫芬顿邮报。”15. GPT-3 paper: “WebText2:190 亿 token。[Alan:WebText2 是从 WebText 稍微扩展而来,所以我们可以减去 20%,得到 150 亿 token]”16. GPT-2 paper: pp3 “GPT-3: pp9, Table 2.2 “CC: 4100 亿 token. WebText2: 190 亿 token. Books1: 120 亿 token. Books2: 550 亿 token. Wiki: 30 亿 token”18. BookCorpus repo: soskek/bookcorpus#27: “books3.tar.gz 似乎类似于 OpenAI 在他们的论文中引用的神秘“books2”数据集。不幸的是,OpenAI 不会提供细节,所以我们对其差异知之甚少。人们怀疑它是“libgen 的全部”,但这纯粹是猜测。尽管如此,books3 仍是“所有的 bibliotik”......”19. BookCorpus paper: https://arxiv.org/abs/1506.06724: “# of words: 984,846,357 [Alan: BookCorpus 有 13 亿 token。我们想要有 120-550 亿 token]”20. Gutenberg paper: https://arxiv.org/abs/1812.08092: “我们介绍了标准化项目古腾堡语料库(SPGC),这是一种开放的科学方法,用于处理完整 PG 数据的精选版本,其中包含超过 50,000 本书和 3×109word-token[Alan:相当于大约 120 亿 BPE token,见下文 ]”21. Gutenberg repo: https://zenodo.org/record/2422561 “未压缩大小:3GB(count)+ 18GB(token)[总计 21GB]”22. The Pile v1 paper: “Books3(Bibliotik tracker):100.96GB” [Alan:乘以每字节 token 数 0.2477 = 250 亿 token]23. The Pile v1 paper: pp3, Table 1 for datasets. pp28, Table 7 for Tokens per byte.24. RoBERTa paper: https://arxiv.org/abs/1907.11692 “BOOKCORPUS 加上英文 WIKIPEDIA。这是用来训练 BERT 的原始数据。(16GB)。”25. BERT paper: https://arxiv.org/abs/1810.04805 “BERT 在 BooksCorpus(8 亿字)和维基百科(25 亿字)上进行训练。”26. Stories paper: https://arxiv.org/abs/1806.02847 pp5-627. RealNews paper: https://arxiv.org/abs/1905.12616v3 “去重后,RealNews 在没有压缩的情况下为 120GB。”28. Gopher paper: https://arxiv.org/abs/2112.11446 pp 7: list of sizes and tokens.29. Gopher paper: https://arxiv.org/abs/2112.11446 pp 44, Figure A3b.30. Gopher paper: pp41n14 “请注意,我们将文档去重应用于除 Wikipedia 和 GitHub 之外的所有 MassiveText 子集“关于作者
Alan D. Thompson 博士是人工智能专家、顾问。在 2021 年 8 月的世界人才大会(World Gifted Conference)上,Alan 与 Leta(由 GPT-3 提供支持的 AI)共同举办了一场名为“The new irrelevance of intelligence”的研讨会。他的应用型人工智能研究和可视化成果受到了国际主要媒体的报道,同时还在 2021 年 12 月牛津大学有关 AI 伦理的辩论中被引用。他曾担任门萨国际(Mensa International)主席、通用电气(GE)和华纳兄弟(Warner Bros)顾问,也曾是电气与电子工程师协会(IEEE)和英国工程技术学会(IET)会员。
(本文经授权后由 OneFlow 编译发布,译文转载请联系 OneFlow 获得授权。原文:https://lifearchitect.ai/whats-in-my-ai/)
相关Wiki
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。