
区块链到底解决了什么实际问题?什么具体的事情是区块链出现之前不能做的,而出现之后能做的?
撰文: Billy,A&T 高级分析师
笔者一直在寻找边际上区块链到底解决了什么实际问题,也就是说,什么具体的事情是区块链出现之前不能做的,而出现之后能做的。这种边际上可行性的改变不易察觉,却可能产生巨大的商业机会。下文是笔者的答案之一。我相信,顺着博弈论的思路,或许还能想到其他可用区块链解决的实际应用场景,并想出新的商业模式,欢迎讨论~
在本文笔者更多使用的是博弈论中的理性人模型解释实然现象,并不再叙述关于「用户应该拥有自己的数据」等 Web3 native 的应然叙事,因为应然叙事已经被讨论的很充分,无需笔者再作分析。
摘要
- 区块链的一大叙事就是模块化:任何人都可以在现有的区块链代码积木上无需许可地增加新的功能,但事实上,世上无新事,传统互联网许多环节也是模块化的,如操作系统。
- permissionless 的操作系统帮所有软件工程师解决了每个软件都要重复造轮子,编写与计算机硬件交互的代码的问题,极大的提升了代码编写的效率,使在其上的生态茁壮成长。
- 与前操作系统时代类似,现互联网数据割裂,每个应用都需重新搜集数据,有严重的重复造轮子问题。Web2 巨头开放数据,建立自身 permissionless 的生态,解决重复造轮子问题,理论上是对其本身和生态都有收益的事情,但却因为类囚徒困境问题(博弈论经典问题)无法达到帕累托最优的结果。
- 具体来说,在区块链诞生之前,没有方法能同时防止数据使用者白嫖和数据提供者反悔这两个问题,从而导致类囚徒困境。本质是,在此序贯博弈中,理性的后行动者总是会选择「欺骗」而不是「合作」。
- 区块链作为信任机器,解决了「不可置信承诺」问题,保证了后行动者的「合作」,使博弈双方可以达到「(合作,合作)」局面,从而使用户数据被开放,成为公用数据层,从而使互联网软件无需重复造轮子成为可能。
序言
区块链的一大叙事就是模块化:任何人都可以在现有的区块链代码积木上无需许可地增加新的功能,减少了大量重复造轮子的浪费,提升了效率。世上无新事,模块化的本质就是在软件领域的 permissionless 的产业链分工。一个典型的例子是,计算机行业发展早期,计算机的硬件和软件由一家企业制作,后续才产生了 permissionless 的操作系统层,大大降低了软件的编写门槛,激发了软件业的活力,诞生了互联网这个万亿级别的市场。
然而,互联网演化到了现在,各种各样的模块化工具使得代码级别的重复造轮子问题已经小了很多。例如,模块化的云数据库让人无需重复设计、搭建、部署复杂的数据管理系统。然而,数据层面的重复造轮子问题却很严重:每个互联网软件都需要重新获得用户数据,这使得用户转换成本巨大,从而使得软件公司的获客成本大大提高,这与当年操作系统还没出现时一样,大大抑制了互联网软件的创新。
明明开放的数据层生态大概率会远远好于封闭的数据层生态,为什么掌握用户数据的 Web2 巨头不愿意开放其数据,作为其他应用软件的数据层呢?原因是,数据提供公司无法防止应用公司白嫖其数据,或者应用公司无法防止数据提供公司反悔收回其数据使用权。抽象来看,本质上是在动态博弈中,因为信任问题而导致在每个个体选择了对自己最有利的决策下,整体利益无法达至最优的问题,类似我们常听的囚徒困境问题。若用博弈论的术语来说,那就是精炼纳什均衡并非帕累托最优解的问题。
区块链作为信任机器,令原本「不可置信的承诺」变得可信,解决了此博弈问题,使得模块化的 permissionless 数据层成为可能。这会大大降低互联网软件的创新门槛,为现在停滞的互联网注入新的活力,为前所未有的创新提供土壤。同时,permissionless 的数据层,也会创造像 permissionless 的操作系统层一样巨大的价值,在其生态茁壮成长的同时,成为下一代互联网的基石。
计算机产业分工发展史:permission 操作系统模块化
1960 年代,大多数主机仍没有交互式界面,整个计算机行业还处于非常原始的状态。当时,硬件和软件都由同一公司制作,不同公司的硬件与软件都不兼容。若是在硬件上编写软件,代码工程师需要用机器语言 / 汇编语言进行编写,甚至连乘法函数都要自己写一遍。
突破发生在 1969 年:面对美国司法部的反垄断压力和内部软件开发成本的不断增长,IBM 改变了计算机行业原有的商业模式:它将停止发送免费软件,未来将开始分别为硬件和软件定价。紧接着,IBM 推出了 IBM/360 计算机,将操作系统进行了标准化。在 20 世纪 70 年代,软件公司第一次可以写出能在全球 80% 大型机上使用的软件。至此,计算机产业链的硬件和软件就成功解耦了。任何软件厂商都可以在 OS/360 操作系统上 permissionless 地编写软件并将之卖给用户。
1981 年,IBM 要求比尔盖茨帮其新计算机编写操作系统,且答应比尔盖茨可以将其操作系统脱离 IBM 的硬件单独进行营销,很快 Windows 操作系统就诞生了。从此以后,操作系统彻底从计算机产业链分离成为单独的一层,紧接着 permissionless 的操作系统催化了这场轰轰烈烈的互联网革命。

操作系统在整个产业链扮演者什么样的角色呢?permissionless 的操作系统层帮软件厂商们解决了与计算机硬件进行交互的问题,从而无需让软件工程师从零开始与硬件交互写软件,而只需要面对操作系统将硬件抽象后的接口编程即可,大大减少了软件的开发成本。否则,每个软件都需要写一套与硬件交互的代码,这将会大大提升软件编写的成本。同时,这种重复造轮子的行为将是极大的效率浪费。这和区块链世界的「模块化」其实是一回事:我们制作了模块化的软件,并 permissionless 地允许任何人在这些模块化软件之上搭建新的软件,从而无需重复造轮子,大大减少成本。
互联网数据层成为了抑制创新的新「轮子」
互联网发展到了现在,软件的编写已经不是最大的成本与阻碍,被垄断的用户数据成为了互联网软件重复造的最大的轮子。对于社交软件,每个软件都需要重新建立用户社交图谱网络;对于内容平台,每个平台都要重新累积用户生产的内容;用户虽然想去使用更有趣好用的新软件,但想想自己的社交关系和过往沉淀内容都还存在原软件之中,于是只能罢手。新软件也因为用户数据被垄断,获客成本太高,从而难以存活。用户数据的被垄断严重影响了互联网软件的创新,新软件只能花大代价忙着拉新用户累积数据,而不是专注于自己的软件创新,就如同在没有操作系统之前,需要使用机器语言编写软件的公司一样。
另一方面,开放的数据层生态会远远好于封闭的数据层生态,就好像开放的操作系统生态(如 Windows)显然会远远好于所有应用软件只由原公司编写的操作系统生态,从而在竞争中胜出。假设腾讯开放了微信的用户数据,那必然有无数创业者蜂拥而至,在其上构建新的软件。若是如此,或许抖音、快手、拼多多等新一代的移动互联网创新应用恐怕都会出现在腾讯的数据层上,而不是让用户重复造轮子,每个软件各自为战。如此,看上去垄断了用户数据的 Web2 巨头将其数据开放出来似乎也有好处。
为什么互联网的数据层没法像操作系统一样分离出来,供所有软件使用,减少重复造轮子问题?能否直接将数据开源?很可惜,答案是不能。使得数据层成为互联网发展的一个开放的分工模块需要做到两点:
1)防止使用者白嫖:设计好的交易结构,防止搭便车问题,让拥有数据的公司有激励开放其数据;
2)防止提供者反悔:设计好的信任机制,减小数据提供商收回数据的权力,让有雄心的创业者放心在此数据层上搭建创新应用,而不必担心做大后权力被收回。
操作系统的 permissionless 模块化则没有以上两种问题:
- 对于 1),操作系统与硬件绑定销售,可获得大量利润,因此它有激励将产品开放给所有人使用,而不是只允许自己在上面编写软件;
- 对于 2),操作系统是一串本地代码,并不存在将已发出的操作系统远程删除的可能,因此软件编写者不必太担心自己做大之后操作系统公司会禁止该软件的使用,而变为自己做以谋取暴利。(不过,操作系统公司有其他方式进行「不正当竞争」,如微软的 IE 成为了 Windows 的预装浏览器,从而在竞争中胜过了当时正红的网景浏览器)
互联网数据层则不然,因此理论上更有效率的开放式数据层并没有在传统互联网出现:
- 对于 1),如果互联网数据巨头直接将用户数据开源,则使用者可以直接白嫖这些没有排他性数据,导致互联网数据公司(如腾讯)没有激励开放数据。
- 对于 2),如果互联网数据巨头使用 API(计算接口)向其他公司提供数据,原公司将一直有能力关闭这些 API。这导致真正有创意有雄心的创业者不会在可被收回的数据层上进行建设,以防止其做大之后被数据层公司要挟。事实上,在过去,无论是微博还是推特,其 API 管的都比较松,也正因此大量围绕着微博和推特的第三方软件出现——它们有着更好更创新的 UX,并且很好地服务了某些不被原软件照顾到的垂类用户。但是,在这些第三方软件做大之后,微博和推特因为被这些较为同质化的第三方软件影响了市占率,微博和推特都大幅降低了其 API 的开放性,以摧毁这些长在自己生态上的竞争对手,重新赢回市占率。
Web2 巨头垄断数据不愿开放是囚徒困境
前文已经叙述了传统互联网数据层诞生的两个最大阻力:无法防止使用者白嫖和无法防止提供者反悔。抽象来看,本质上是在动态博弈中,因为信任问题而导致在每个个体选择了对自己最有利的决策下,整体利益无法达至最优的问题,类似我们常听的囚徒困境问题。若用博弈论的术语来说,那就是精炼纳什均衡并非帕累托最优解的问题。我们先用博弈树来解释无法防止使用者白嫖而导致无法达至最优解的问题。
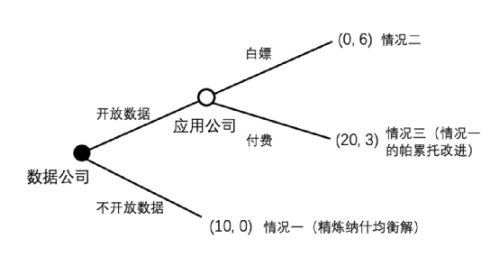
在此次动态博弈中,数据公司(也就是如腾讯等拥有数据的 Web2 巨头)有开放数据和不开放数据的选择。若其开放数据,应用公司可以选择白嫖或者不白嫖。在博弈树的叶子结点,括号内第一个数表示数据公司的效用,第二个数表示应用公司的效用。
这颗博弈树描述了如下情况:
- 情况一:如果数据公司选择不开放数据,也就是现在的 Web2 巨头垄断数据的情况,数据公司效用为 10,而应用公司无法使用现有数据,只能重复造轮子,因此效用为 0。
- 情况二:如果数据公司选择开放数据作为互联网应用的数据层,而应用公司选择白嫖,因为数据公司从此没有了壁垒且无法盈利,数据公司效用为 0;而应用公司因为免费获得了大量数据,无需重复造轮子,因此效用为 6。
- 情况三:如果数据公司选择开放数据作为互联网应用的数据层,而应用公司选择付费,那么因为之后会有大量创新公司长在该数据层上,其生态会变得非常壮大,且其可以借助其生态获得更强的盈利能力(就像微软和以太坊一样),因此数据公司效用为 20;而应用公司,虽然付出了一些金钱,但是获得了用户数据,无需重复造轮子,大大减小了获客成本,因此效用为 3。
我们可以很容易发现,情况三(20,3)是情况一(10,0)的帕累托改进。也就是说,无论是对于数据公司还是应用公司,情况三都要好于情况一的(20>10,3>0),为什么情况没有往这个方向演变呢?原因是,精炼纳什均衡解就是情况一。直观来看,假设数据公司和应用公司都是理性的情况下,情况三是不可能达成的:如果数据公司先选择了开放数据,让所有应用公司都可以使用数据的话,应用公司一定会选择白嫖而不是付费,因为这样对于应用公司效用最高(6>3),从而使博弈树走到情况二。数据公司不是傻子,他很清楚一旦他直接开放数据,如果没有手段使数据变成排他性资产的话,应用公司不会付费(二阶理性),会导致情况二。因此,对于数据公司来说,不如一开始就不开放数据,从而进入比情况二更好的情况一。因此一开始数据公司就不会开放数据。
如果应用公司声称他会付费,让数据公司开放数据,实现合作共赢,这样可以达至集体最优的情况三吗?答案是很难,因为应用公司声称他会付费是一个「不可置信承诺」,有很大的事后反悔的动机,很难令人相信,而用法律的协调成本则太高。
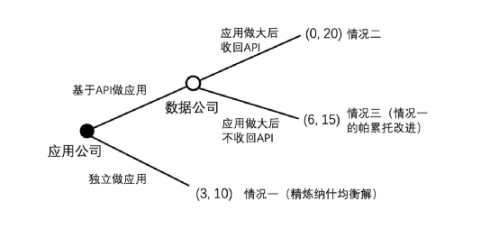
无法防止数据提供者反悔问题也同样可以用博弈树进行分析,是类似的问题,最后的结果则是无法达到(6,15)的帕累托最优解,而是只能被困在(3,10)的囚徒困境中。读者可根据下图自行推演。
区块链有潜力解决博弈问题,使数据层模块化成为可能
Web2 巨头不愿开放其数据并非不知道成为一个开放生态的好处,而是因为以上博弈问题,从而导致没法走向使每个人都获益的情况三。就像囚徒困境一样,每个人都会选择「坦白」,而无法走向每个人都不坦白从而免去牢狱之灾的(3,3)。
上文提出的一个可能的解决方案是,博弈树中的后选择者可以声称合作(如声称付费),诱使先选择者也进行合作(如开放数据)。但问题在于,在传统场景中,声称会合作是「不可置信承诺」,因为在先选择者合作之后,后选择者反悔才是利益最大化的选项。这里的重点在于人的「不可置信」。而区块链正好是解决信任问题的,写入了区块链的代码将无法被更改,无法反悔,因此区块链正是解决此类问题的关键!
对于无法防止使用者白嫖的问题,数据公司可以把数据放进区块链中,并且编写合适的代码使得需要付出 token 才能调用相应数据(也许需要一定隐私加密技术),甚至就直接学以太坊,让使用者需要付出 token 才能储存数据。这样一来,应用公司就可以 permissionless 地付费调用 / 储存数据(这里可以设置成只有用户使用私钥才能调用自己数据,以做到用户拥有自己的数据,然后应用公司帮用户付费),而数据公司也可以不必担心应用公司直接复制数据而不付钱了。
对于无法防止提供者反悔的问题,数据公司可以把数据放进区块链中,并且编写合适的只要付钱才可以调用数据的代码就可以解决。因为区块链是不可篡改而且 permissionless 的,应用公司无需担心数据公司有一天会将权限收回,因为数据公司无法收回。
注意,这里的收费可以按多种模式,如按次收费,按 DAU/MAU 收费,按 license 收费等。每次收费也可以很低以减小应用公司负担,如每天每个 DAU 0.1 美分。
如此一来,博弈树将会走到情况三,数据公司和应用公司都将大量获利。
至此,建立数据层将会成为互联网的一种新的商业模式,无数创新应用将会建立在此数据层之上。对于数据公司来说,无数应用公司给数据层公司付费的同时还会不断丰富数据层的数据,壮大其生态,成为互联网下一个操作系统级别的机会。对于应用公司来说,它们的获客成本大大降低(因为用户的转换成本降低),无需重复造轮子,可以专注在产品创新之上,大大增加互联网应用层的活力。边际来看,这种互联网数据层以前无法发生,而现在有机会出现的原因就是区块链解决了信任问题,从而使上述博弈问题得到解决,从而使人们能真的达到囚徒困境中的(3,3)。
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。






